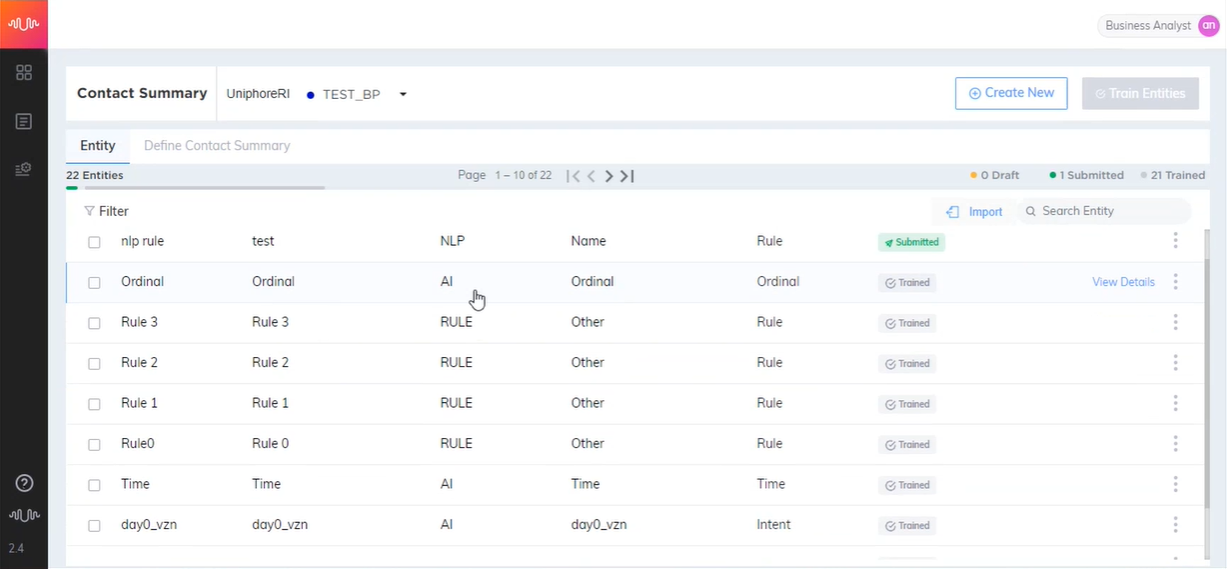
Working with Entities
This feature allows an Analyst to configure Entities such as Customer Name, Booking Date, Date of Birth, Room Rate, etc., based on the conversation between the Agent and the Customer. These Entities must be linked to the same Entity Type in the Entity Catalog. It helps auto-summarization of the contact in real-time.
For more information on Entity Catalog Controller, click here.
Types of entities
NLP Entity | Complex Entity | AI Entity | Rule Entity | |
|---|---|---|---|---|
What | Uses trained AI models that leverage keyphrases in the transcript | Retrieves data from external data sources |
|
|
When is it detected | Every turn | Every time on-demand summary is triggered or at end of call | Every turn | Every time on-demand summary is triggered or at end of call |
Can be used in Rules? | Yes | Yes | Yes | Yes |
Can be used in Contact Summary? | Yes | No | Yes | Yes |
Important
NLP Entities and Rule Entities defined with 'Other' Entity Types will be listed on the X-Console Entities page, under the AI Model page, and mapped with the X‑Platform Session Variable.
Quick Navigation
Analyst can navigate to the following modules from the left pane.
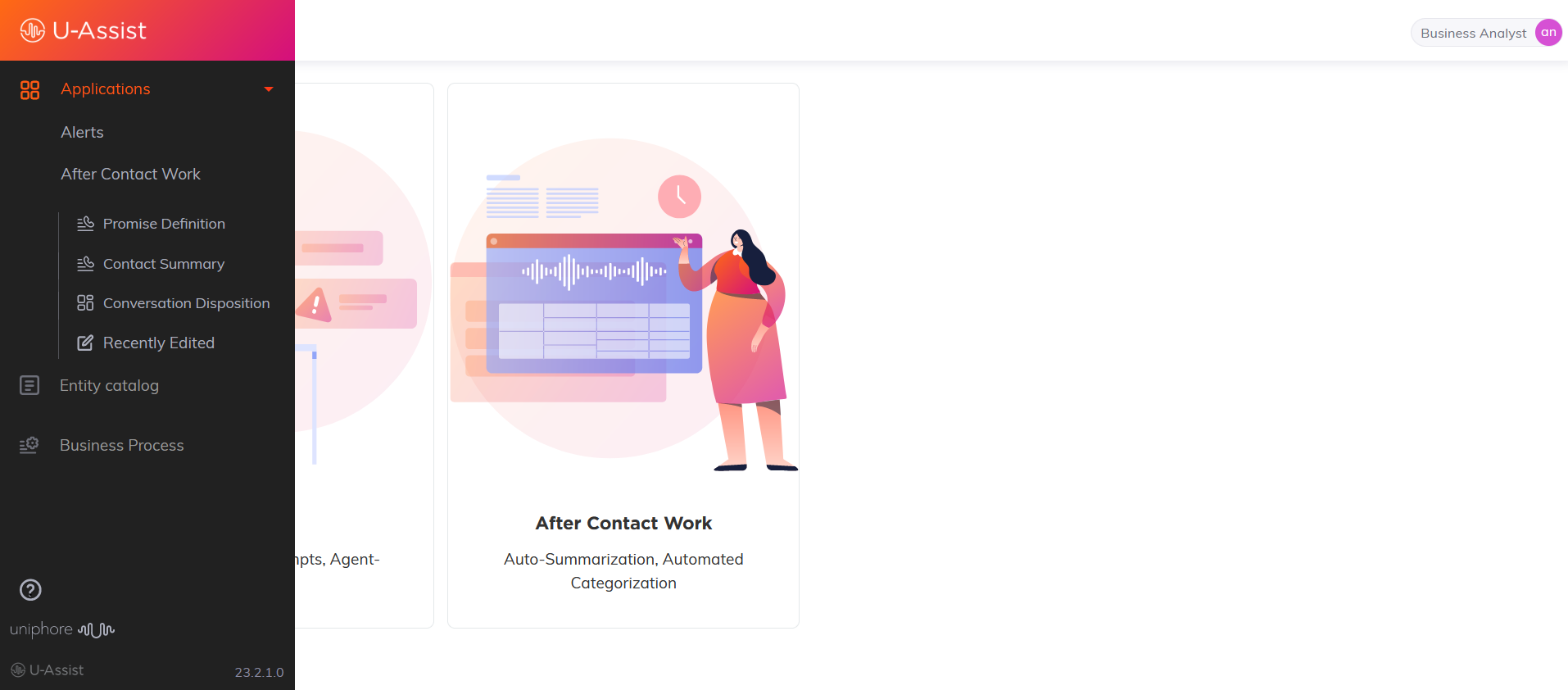
 Applications
Applications
Click to create/configure Alerts, ACW Contact Summary and ACW Conversation Disposition
Alerts
After Contact Work
Promise Definition
Contact summary
Conversation Disposition
Recently Edited
 Entity Catalog
Entity Catalog
Click to display the list of entity catalogs with AI entities. The catalog reference list is at the Tenant level. Multiple entity catalog lists at organization/business process level are not allowed. Analysts cannot edit/add entities in the entity catalog reference.
 Business Process
Business Process
Click to setup a business process for an Organization
 Question Mark
Question Mark
Click to navigate to the Help file.
 Uniphore Logo
Uniphore Logo
Click to navigate to the Home page.
At the bottom of left pane, Analyst can view the version of application.
View Business Process Dashboard
This is a dashboard for the Analyst to view details of configurations of Contact Summary and Conversation Dispositions. Tiles on the dashboard are ordered by how recently each business process was accessed by the user.
The search field allows you to search for Business Process, Entities, Categories. Enter a minimum of 3 characters to start searching for the same.

Each tile has the following sections:
Promise Definition: It shows the number of promises configured for the Business Process, in Drafted, Submitted and Trained status. The total number of promises for a business process is displayed inside a doughnut chart. If you click the "Train" button next to the Submitted status, the submitted promises for the business process will be trained.
Contact Summary: It shows the number of entities configured for the Business Process, in Drafted, Submitted and Trained status. The total number of entities for a business process is displayed inside a doughnut chart. If you click the "Train" button next to the Submitted status, the submitted Entities for the Contact Summary will be trained.
Conversation Disposition: It shows the number of submitted Disposition Categories configured for the Business Process. If you click the "Train" button next to the Submitted status, the Categories for the Conversation Disposition will be trained.
Recently Edited: It shows the number of summaries, entities (non-Rule type), and dispositions in this Business Process that were edited by agents when they submitted the Contact Summary from within the Agent Console. You can select a date option to filter this number by date.
Today - Shows the number of summaries, non-Rule type entities, and dispositions within the business process that were edited in the last 24 hours. By default, this option is selected.
WTD - Shows the number of number of summaries, non-Rule type entities, and dispositions within the business process that were edited from the beginning of the week (Monday 00.00.00 hours) till date.
MTD - Shows the number of number of summaries, non-Rule type entities, and dispositions within the business process that were edited from the 1st day of the month till date.
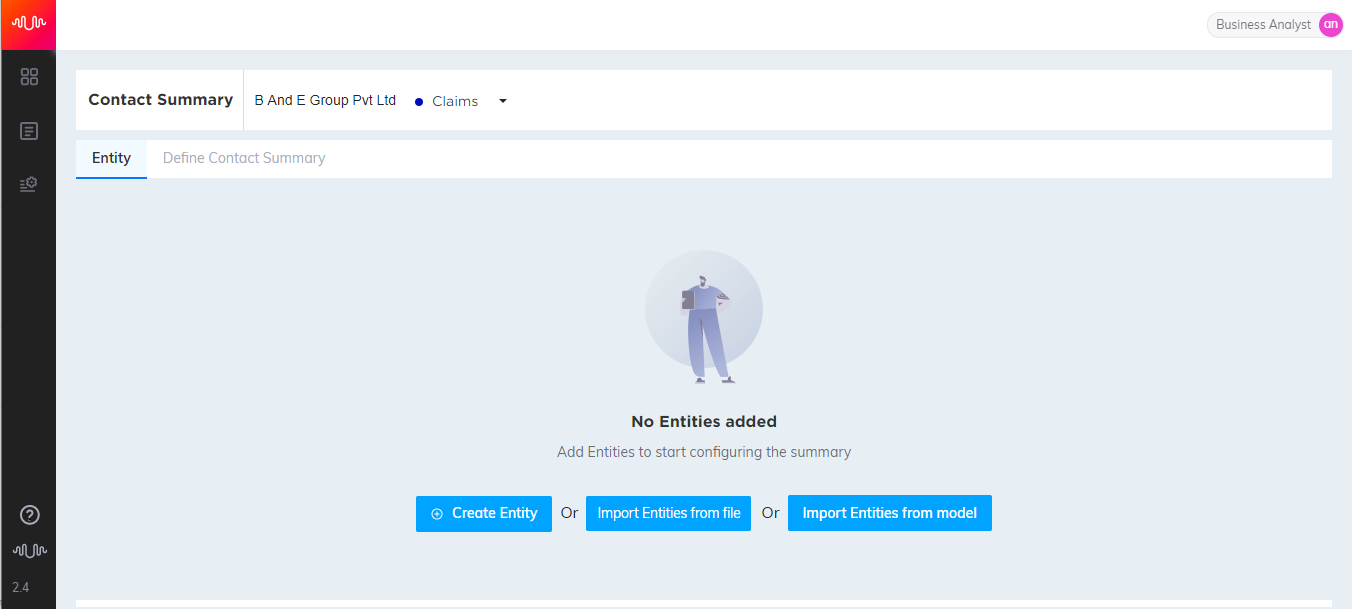
Define NLP Entity
NLP Entities are detected based on a combination of NER (Named Entity Recognition) models and configured key phrases in the transcript. The steps to define entity are listed below:
In the Home page, select Applications > After Contact Work > Contact Summary from the left pane.
In the top of the page, select Organization and Business Process from the drop-down list.
Click Create Entity button to navigate to Define Entity page.
Enter meta data of the intent in the Entity Name field. If you provide invalid characters, an error message will be displayed.
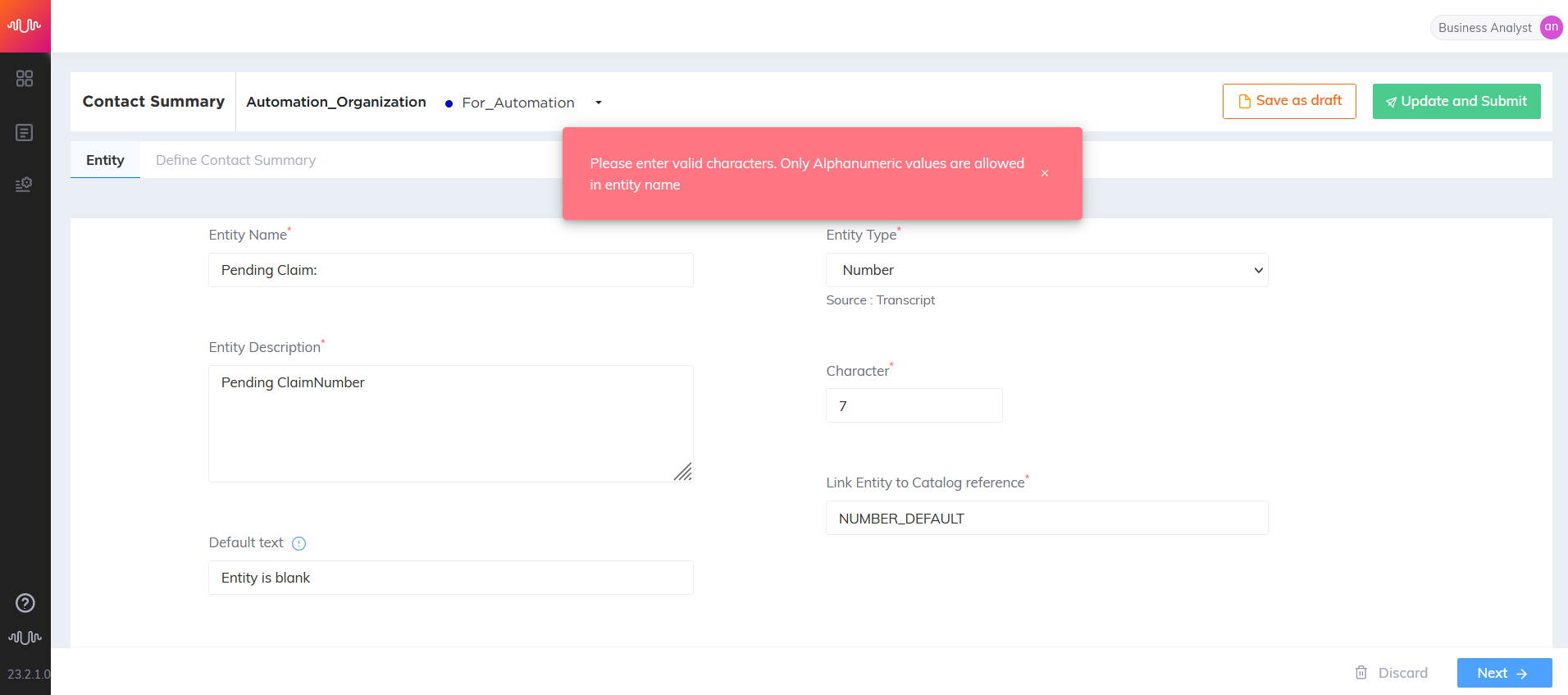
Enter the description for meta data of the intent in the Description field.
Select any one of the below data types from the Entity Type drop-down list. If you select the Entity Type as 'Number' mention the number of characters required for this type.
For more information on built-in Entity types, click here.
Refer to the section "Configure entity types" for each entity type configuration with different use cases and examples.
Select an associated entity catalog from the drop-down list to link the entity with the catalog.
Click Next button to navigate to Search from conversation page.
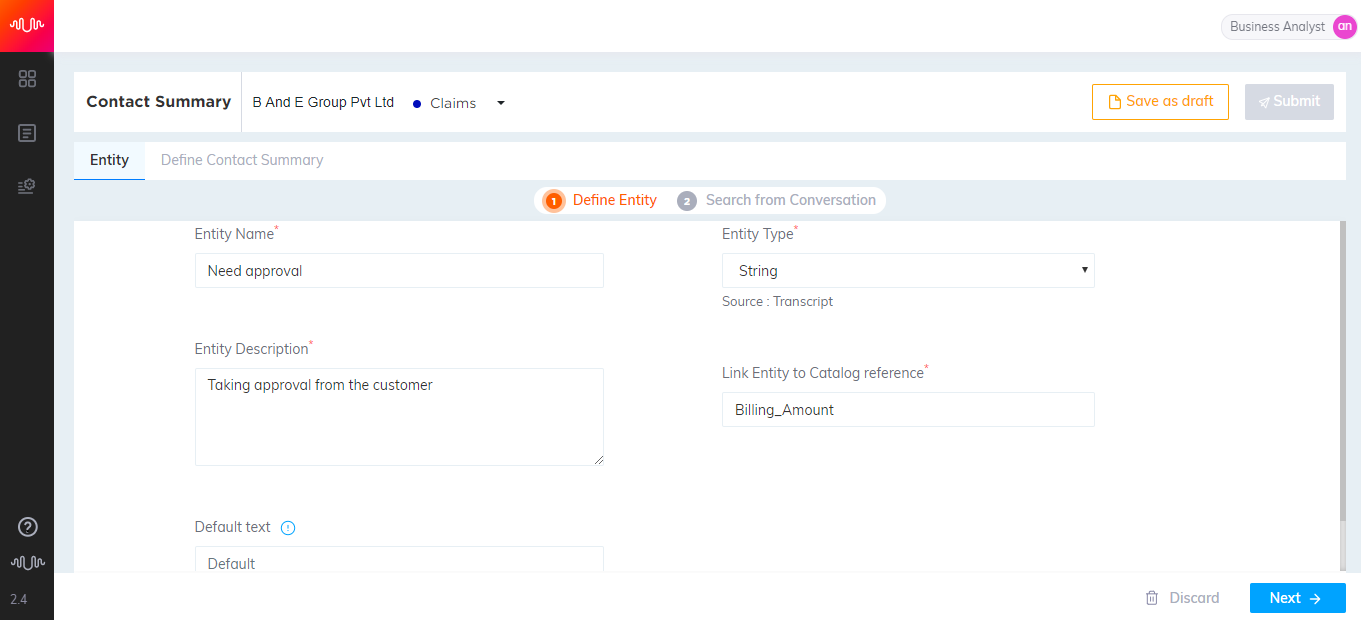
Note
If you want to continue working on configuration of Entity at a later point of time, click Save as draft button to save Entity as a draft.
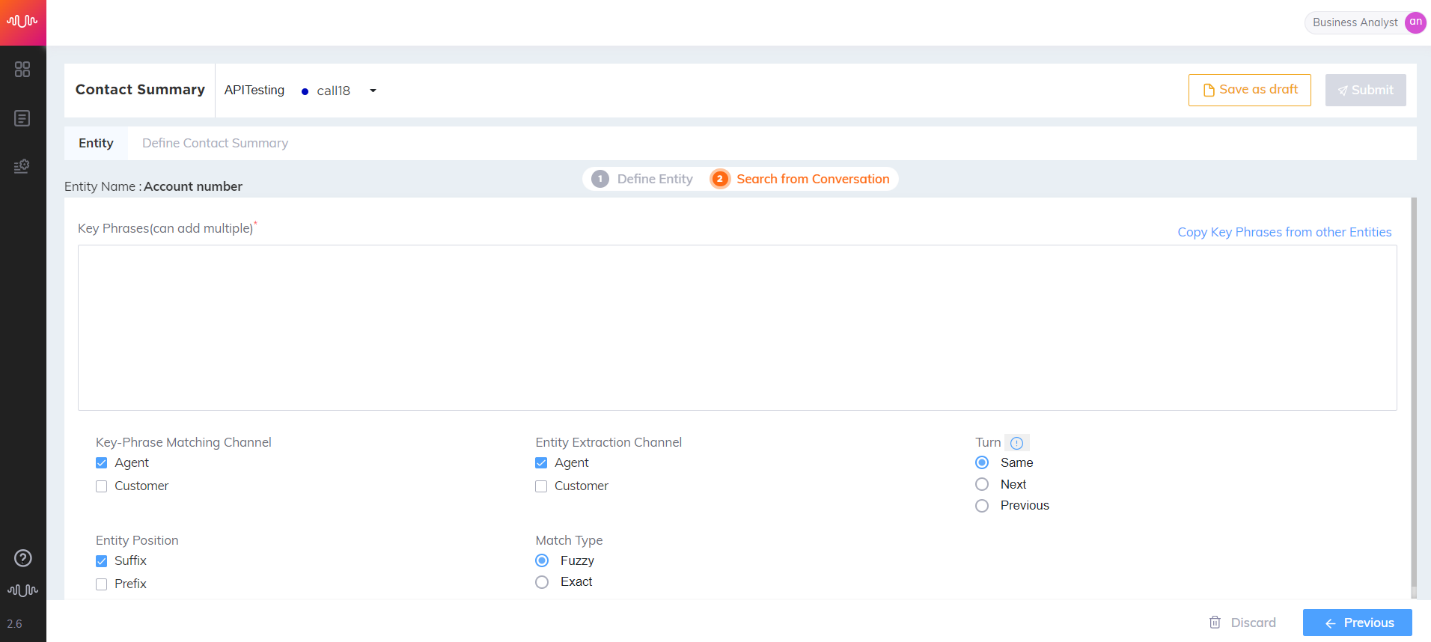
The next step in entity definition is to manually add or import multiple keyphrases to the corresponding entity.
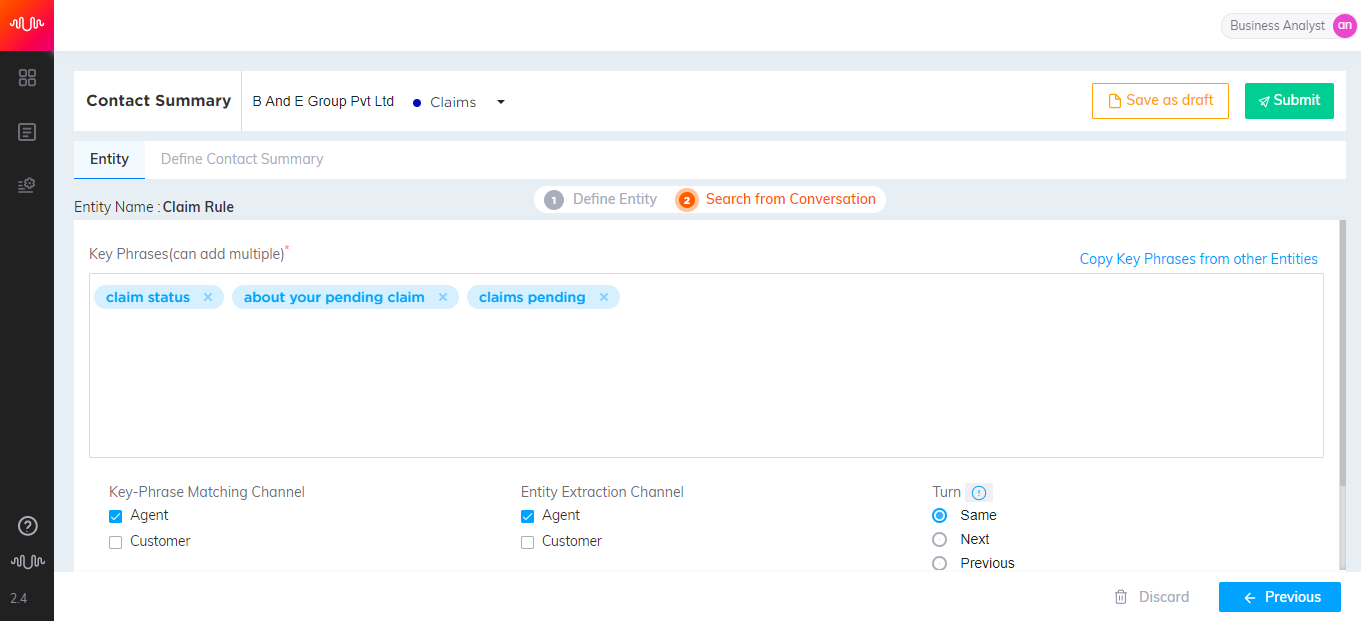
By default, entity name is displayed at the top of the page.
Enter the Keyphrases for the entity. Analyst can import multiple keyphrases at the same time from Excel, a .txt file or clipboard. These keyphrases should be separated by a new line character. If any duplicate keyphrases exist in the source, the keyphrases will not be imported. After importing keyphrases, a confirmation message showing the number of keyphrases successfully imported and number of duplicate keyphrases failed to be imported will be displayed.
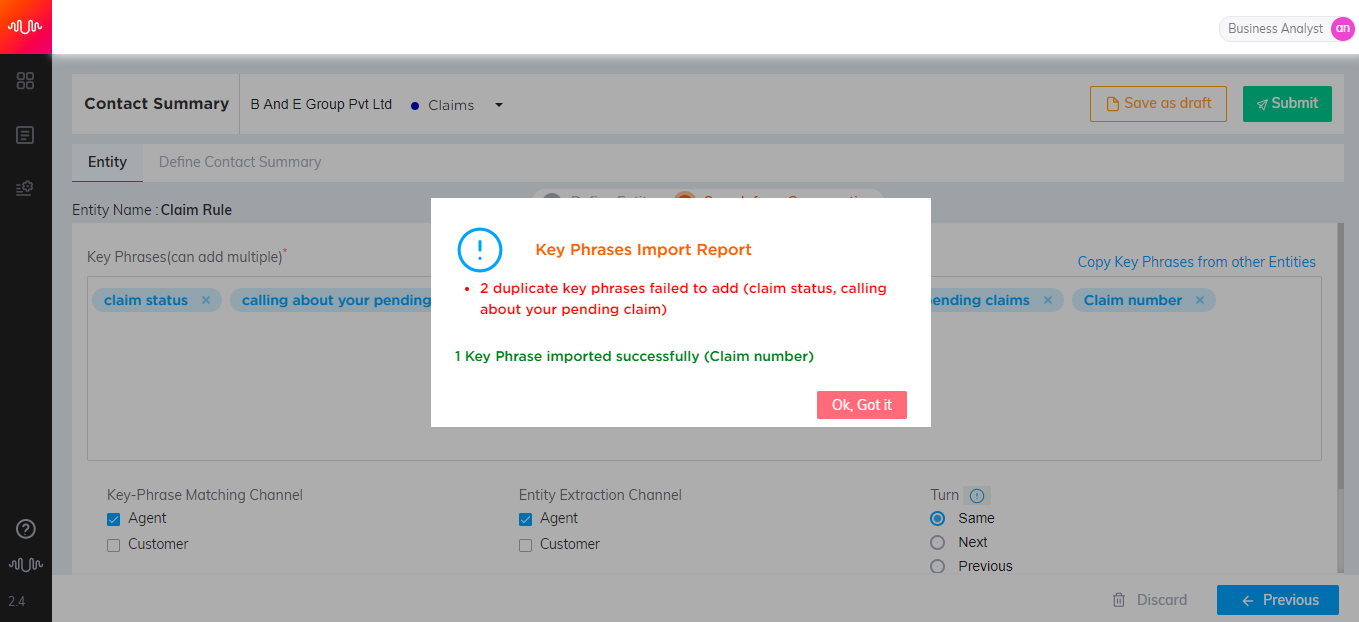
For copying keyphrases from other Entities, click here.
Double click on the keyphrases to make any changes and hit enter.

Select a speaker channel (Agent or Customer) in the Keyphrase Matching Channel field.
Agent – Configured keyphrase will be detected in Agent Channel.
Customer – Configured keyphrase will be detected in Customer Channel.
Select a speaker channel in the Entity Extraction Channel field.
Agent – Entity value will be extracted from Agent Channel.
Customer – Entity value will be extracted from Customer Channel.
Select the turn from which you want to extract entity valuesfrom the configured channel. Based on the selection, values are extracted in the turn relative to the turn where the keyphrase was found – preceding, succeeding or the same conversational turn.
Same - Entity value will be extracted from same conversation turn as the turn where the keyphrase was detected
Next - Entity value will be extracted from the turn succeeding the turn where the keyphrase was detected
Previous - Entity value will be extracted from the turn preceding as the turn where the keyphrase was detected.
Note
For the purposes of entity configuration, a turn is a pair of utterances by each channel – agent and customer
Selection of multiple values in a turn is not allowed.
Selection of Entity Position (Prefix or Suffix) is allowed only for the turn option - "Same".
Select any of the Entity Positions. By default, both the options are selected
Suffix – Entity value will be positioned after the keyphrase.
Prefix – Entity value will be positioned before the keyphrase.
Note
Selection of Prefix and Suffix is allowed only if the keyphrase matching channel and entity extraction channel are same.
Select any one of the Matching options.
Fuzzy – Variants related to the configured keyphrase will be considered for the corresponding entity. It helps to detect the intents of the Agent and Customer on the call automatically with very minimal key phrase configuration by the Analyst.
For example, if keyphrases “Date of Service” and “Service Date” are configured for Entity, it will automatically consider the keyphrase “Serviced on” from the call.
Exact – Accurate configured keyphrases will be considered for the corresponding entity.
For example, if keyphrase “Date of Birth” is configured for Entity, it will only consider the keyphrase “Date of Birth” from the call.
If you want to continue working on the configuration of Entity at a later point in time, click the Save as Draft button to save Entity as a draft. Otherwise, click the Submit button. The newly created entity will be listed in the Entity page. A confirmation message will be displayed as shown below, after submitting the entity.
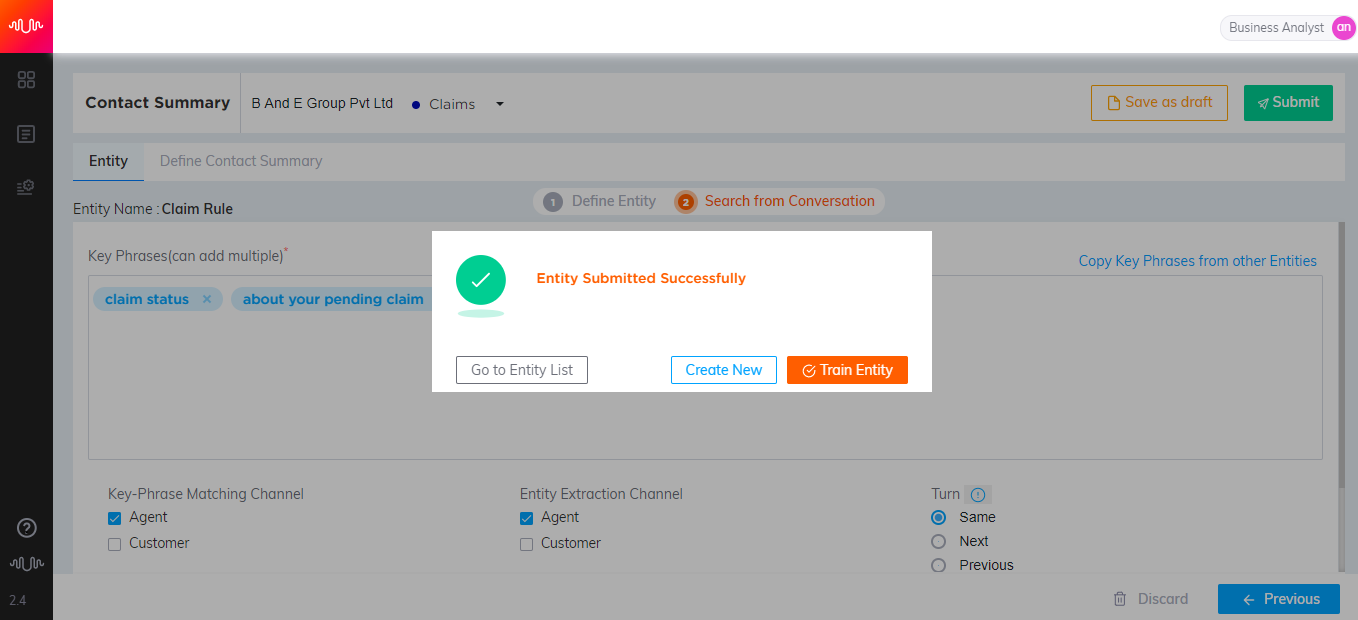
Based on the requirements, select any of the below options:
Go to Entity List - To navigate to the Entity List page.
Create New - To create a new entity.
Train Entity - To train the newly created entity.
Configure NLP entity types
Analyst can configure each entity type with different set of configuration parameters including keyphrase matching channel, entity extraction channel, turn from which entity value will be extracted, entity position and match type.
Given below are the NLP entity types described with different use cases and examples how the entity values are extracted based on the entity configuration:
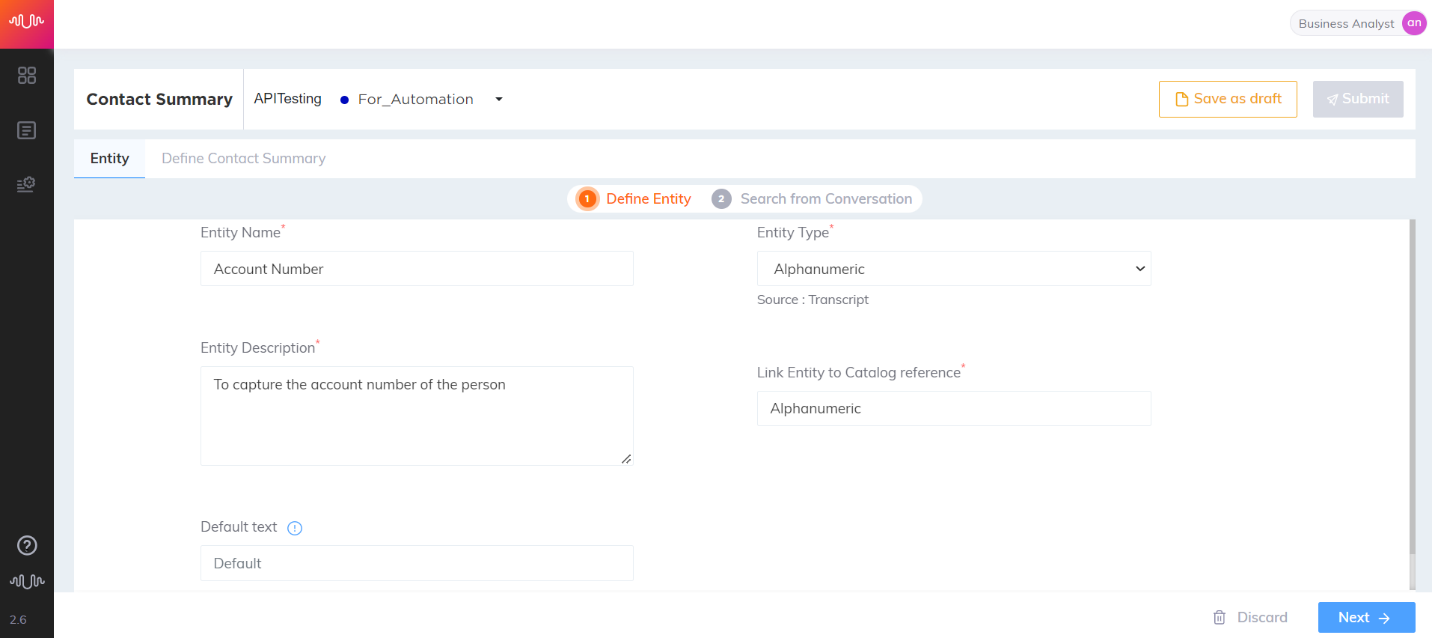
Alphanumeric Entity
Entities which contain alphanumeric characters, i.e., numbers 0 to 9 and/or characters A to Z.
Example: X33456, M B H J 1106, E 66501, etc.,
Generic use case
Transcript:
Agent: Please confirm your account number
Customer: Yes sure. It is A one two four nine seven
Entity configuration:
Name: Account Number
Entity Position: Both Prefix and Suffix
Keyword Matching Channel: Both Agent and Customer
Entity Extraction Channel: Customer
Configure Keywords: “account number” “account id” etc.,
Entity value: A12497
 |
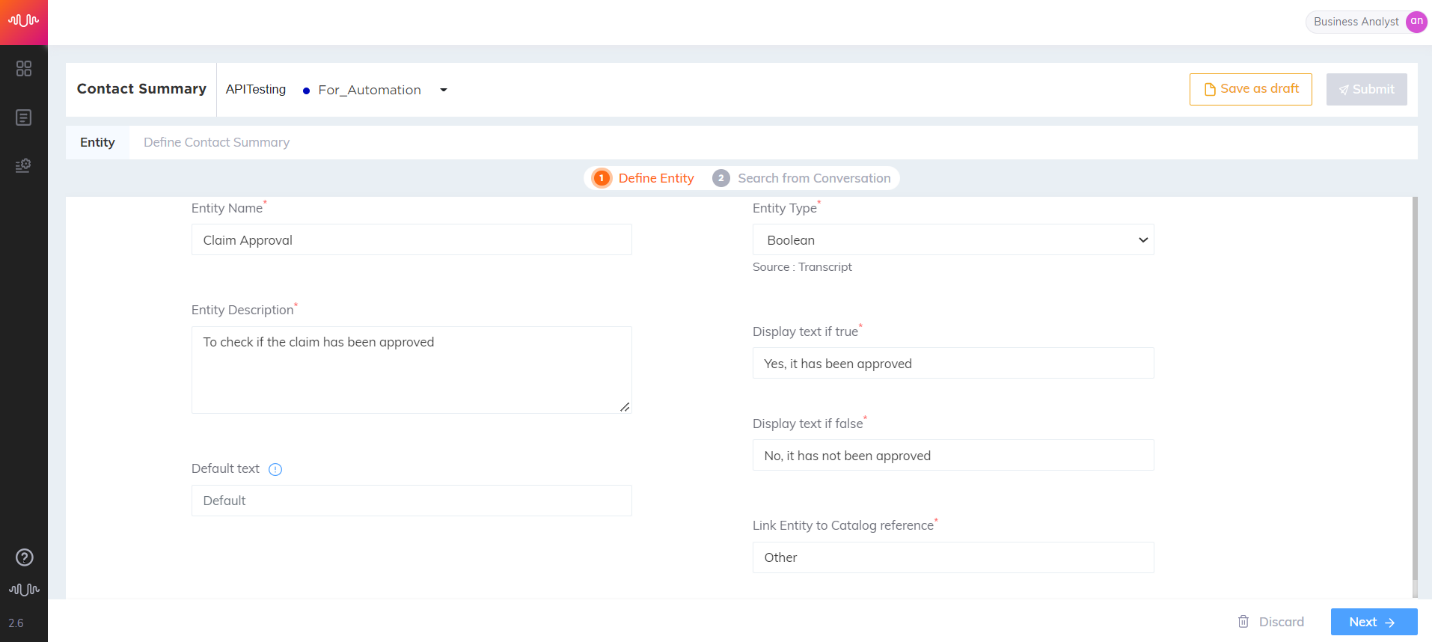
Boolean Entity
Entity which returns a Boolean value.
(Affirmation based on the agent or customer’s colloquial response to a question – for example, yes/yup/yeah or no/nope response.)
Healthcare use case
Transcript:
Customer: Is my claim approved?
Agent: Yeah, your claim is approved.
Entity configuration:
Name: Claim Approved
Entity Position: Both Prefix and Suffix
Keyword Matching Channel: Agent channels are “checked”
Entity Extraction Channel: Agent channels are “checked”
Configured Keywords: “claim approved” etc.,
Entity Value: True
 |
Best Practice: More than other entities, this entity is more dependent on the configured keyphrases. So please pay attention to the keyphrases, as we rely on negation words to return True or False, which may not be predictable for other languages.
Number Entity
Entity which contains numerals that do not fall under any other entity type.
Generic use case
Transcript:
Agent: Can you please confirm your mobile number?
Customer: Yes, it is nine eight seven six five four three two one zero
Entity configuration:
Entity Name: Phone Number
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Agent and Customer channels are “checked”
Entity Extraction Channel: Customer channel is “checked”
Key Phrases added are: “phone number” “mobile number”
Entity Value: 9876543210
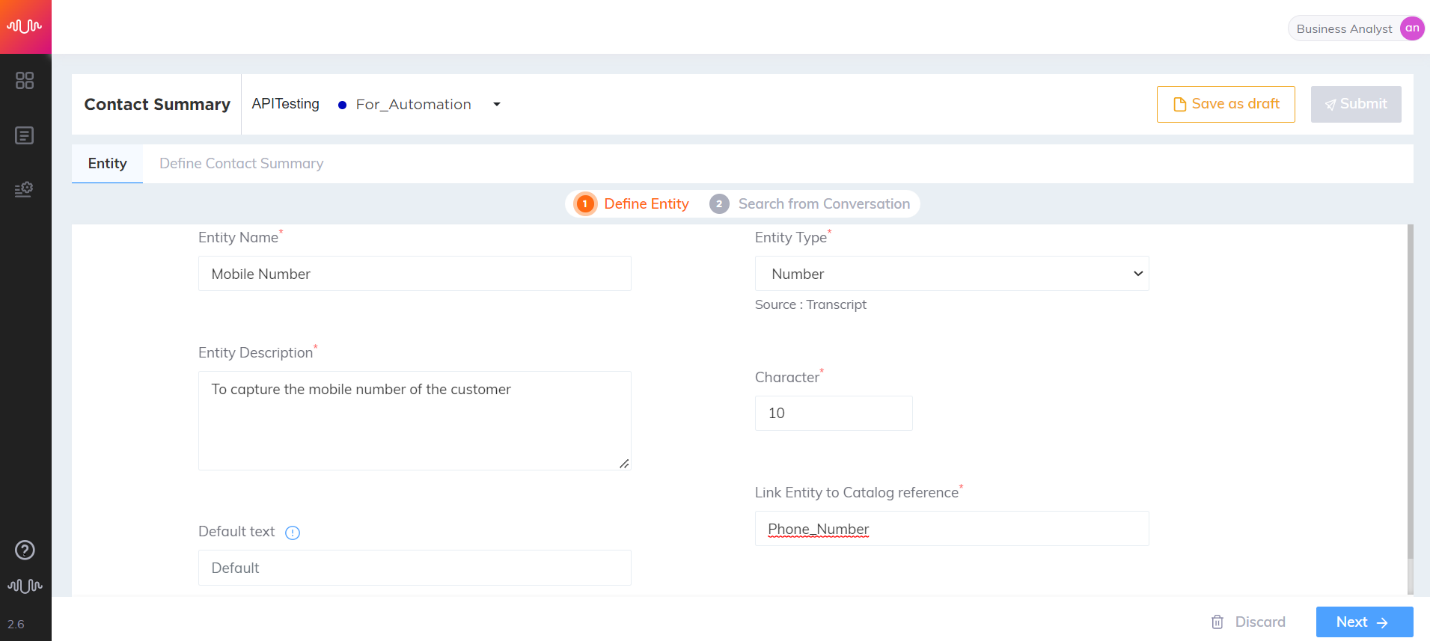 |
Date Entity
Entity which contains any date or date range.
Example: 11/20/2020, 05/20/20 to 05/25/20.
Telecom use case
Transcript:
Agent: We have identified that there is probably an issue with your modem. I have scheduled for an appointment to have one of our technicians visit your house and rectify the issue on Friday, the twenty fifth of September at Three pm. Is there anything else that I can assist you with
Customer: Nothing else. Thanks
Entity configuration:
Entity Name: Appointment Date
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Agent channel is “checked”
Entity Extraction Channel: Agent channel is “checked”
Key Phrases added are: “appointment” “scheduled”
Entity Value: 09/25
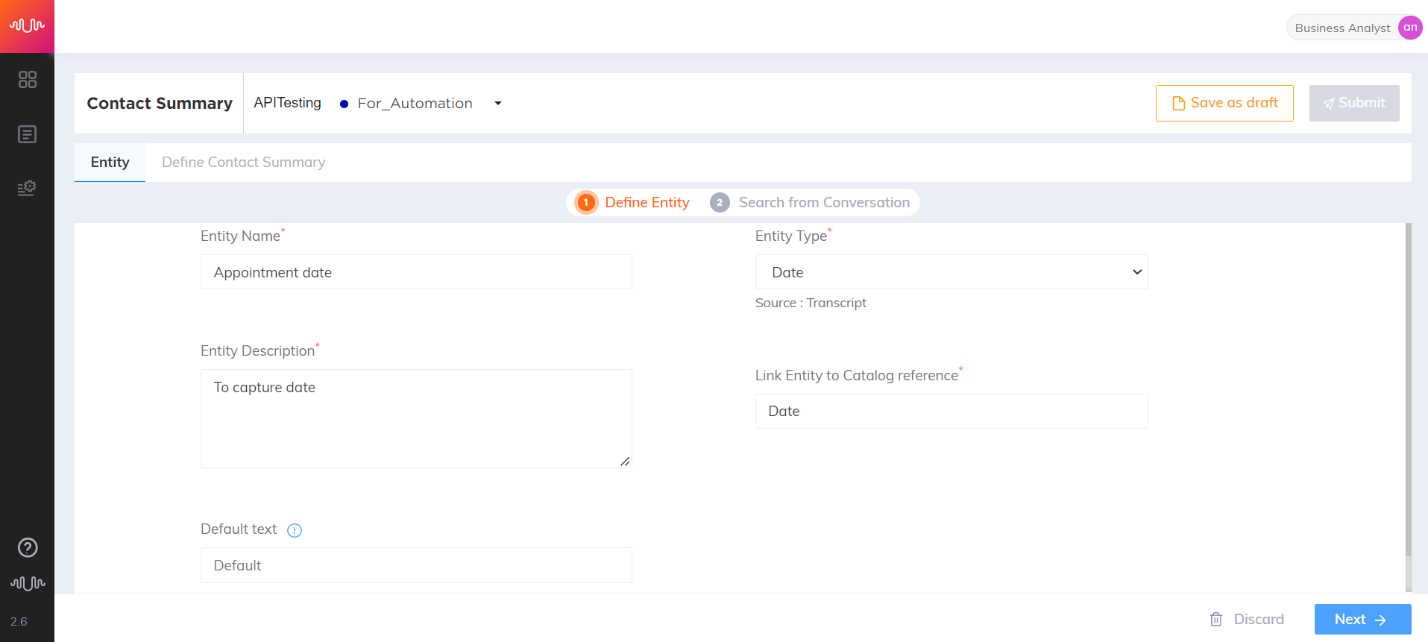 |
Best Practices:
Simple relative dates such as today, yesterday, last month, etc., are also covered.
Recommend to customers about training agents in such a way that dates are always spoken by agents in a prescribed structure for good accuracy in model detection.
Date Time Duration Entity
Entity which contains a combination of date, time, and duration, or any three of these Entity types individually. This Entity type helps to extract date, time and event duration values from transcripts using a prescribed structure.
Example: tomorrow | 5:00 p.m, 3/3/2024 , 8/25/ | 4:00 p.m, yesterday | 6:00 p.m
Telecom use case
Transcript:
Agent: We have identified that there is probably an issue with your modem. I have scheduled for an appointment to have one of our technicians visit your house and rectify the issue on Friday, the twenty fifth of September at three pm. Is there anything else that I can assist you with?
Customer: Nothing else. I am good
Entity configuration:
Entity Name: Appointment Time
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Agent channel is “checked”
Entity Extraction Channel: Agent channel is “checked”
Key Phrases added are: “appointment”, “scheduled”
Entity Value: Friday | 9/25 | 3 p.m
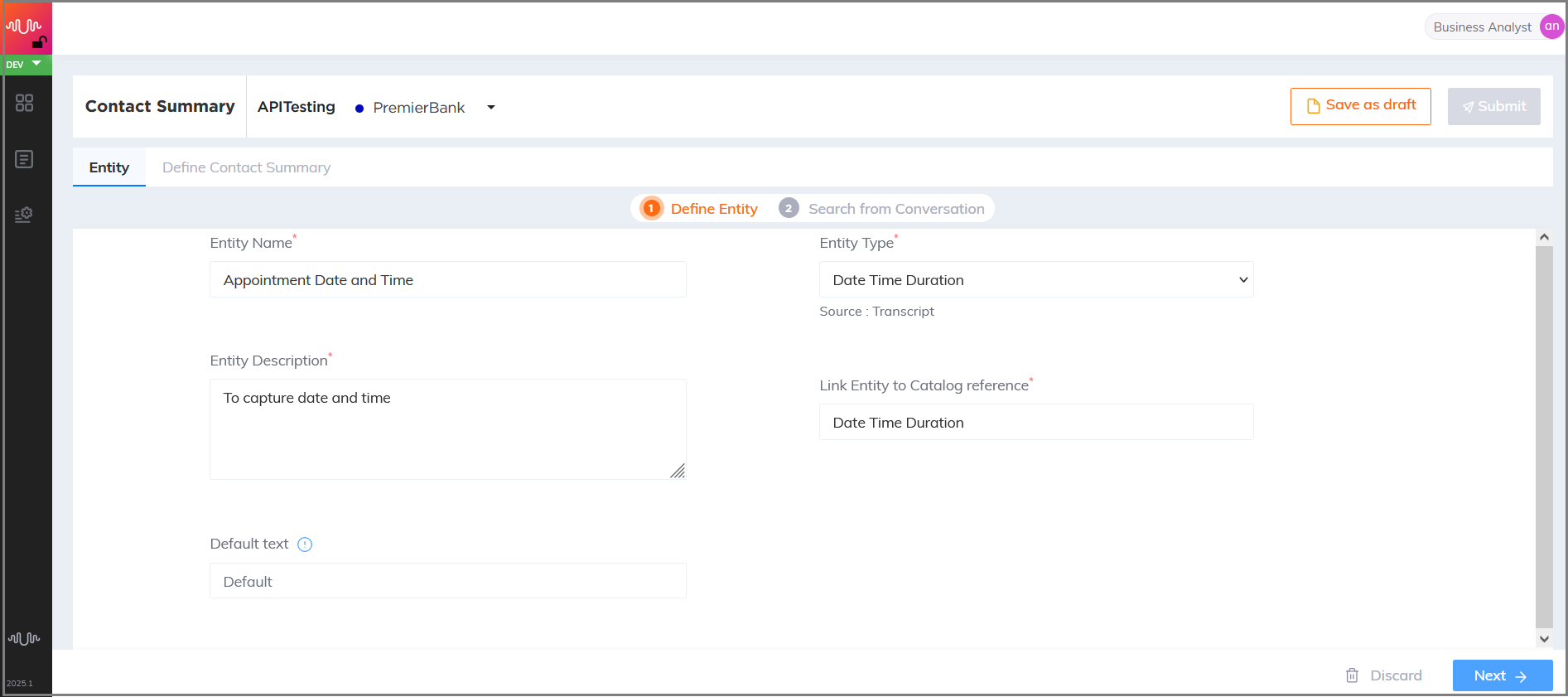
Best Practices:
Recommend to customers about training agents in such a way that date and time are always spoken by agents in a prescribed structure for good accuracy in model detection.
Duration Entity
Entity which contains a duration of time in days, weeks, months or years.
Example: 7 days, 5 business days, 2 to 3 weeks/months/years.
Travel use case
Transcript:
Agent: Your check-in date is on the twenty-third of October. And for how many days will you like to have this sea view room booked?
Customer: Four days.
Entity configuration:
Entity Name: Booking duration
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Agent and Customer channels are “checked”
Entity Extraction Channel: Customer channel is “checked”
Key Phrases added are: “room booked” “room booking” “check in” “number of nights” “number of days”
Entity Value: 4 days
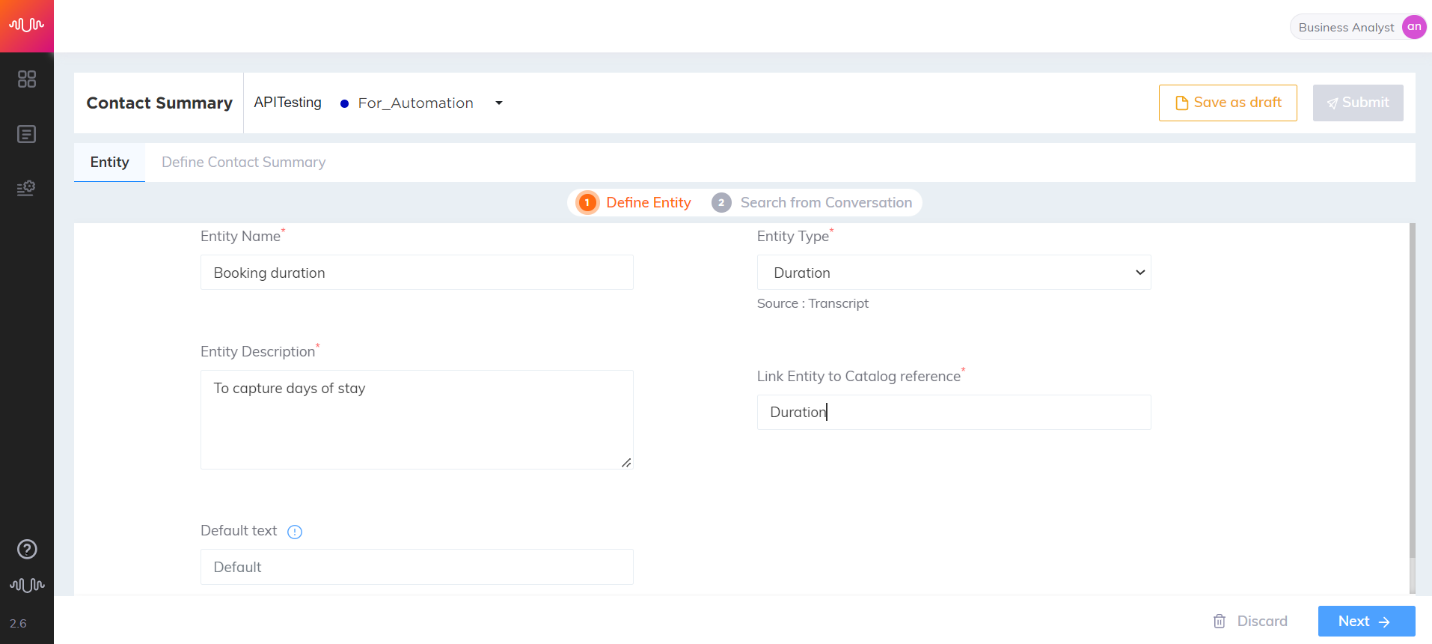 |
E-Mail Entity
Entity which defines any email id(s).
BFSI use case
Transcript:
Agent: Can I please get your email id?
Customer: Yeah sure. It is j for January, o for October, h for Holland n for New York at gmail.com
Entity configuration:
Entity Name: Email ID
Entity Position: Prefix and Suffix checked
Key-Phrase Matching Channels: Agent and Customer channels are “checked”
Entity Extraction Channel: Customer channel is “checked”
Key Phrases added are: “mail id” “email” “email ID”
Entity Value: john@gmail.com
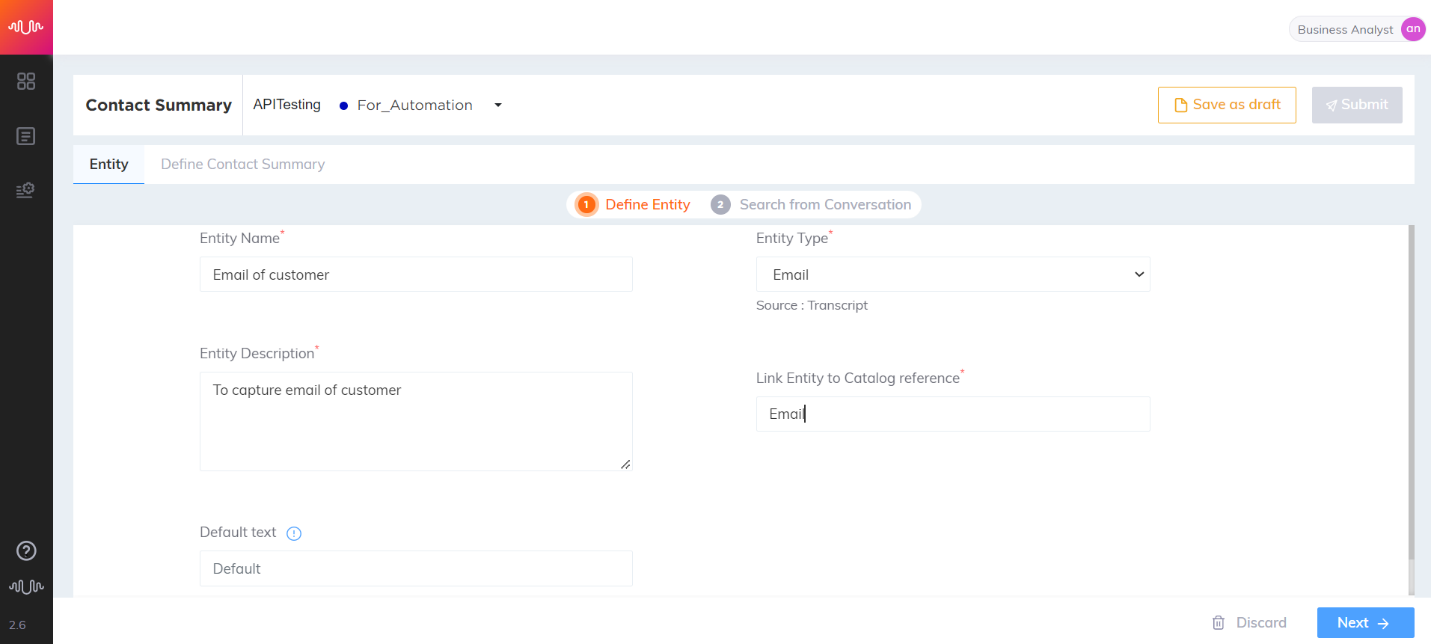 |
Best Practice: Do not use this entity type unless you absolutely need to. Please contact PM (Product Management) and DS (Data Science) before using.
Float Entity
Entity which contains any floating-point numbers.
Example: 7.8, 45.56, 5 point 6
Retail/Real Estate use case
Transcript:
Agent: Can I have your document number?
Customer: sure it's forty three point fifty six
Entity configuration:
Entity Name: Document Number
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Agent channel is “checked”
Entity Extraction Channel: Customer channel is “checked”
Key Phrases added are: “Can I have your document number” “Document number please” “please share your document number”
Entity Value: 43.56
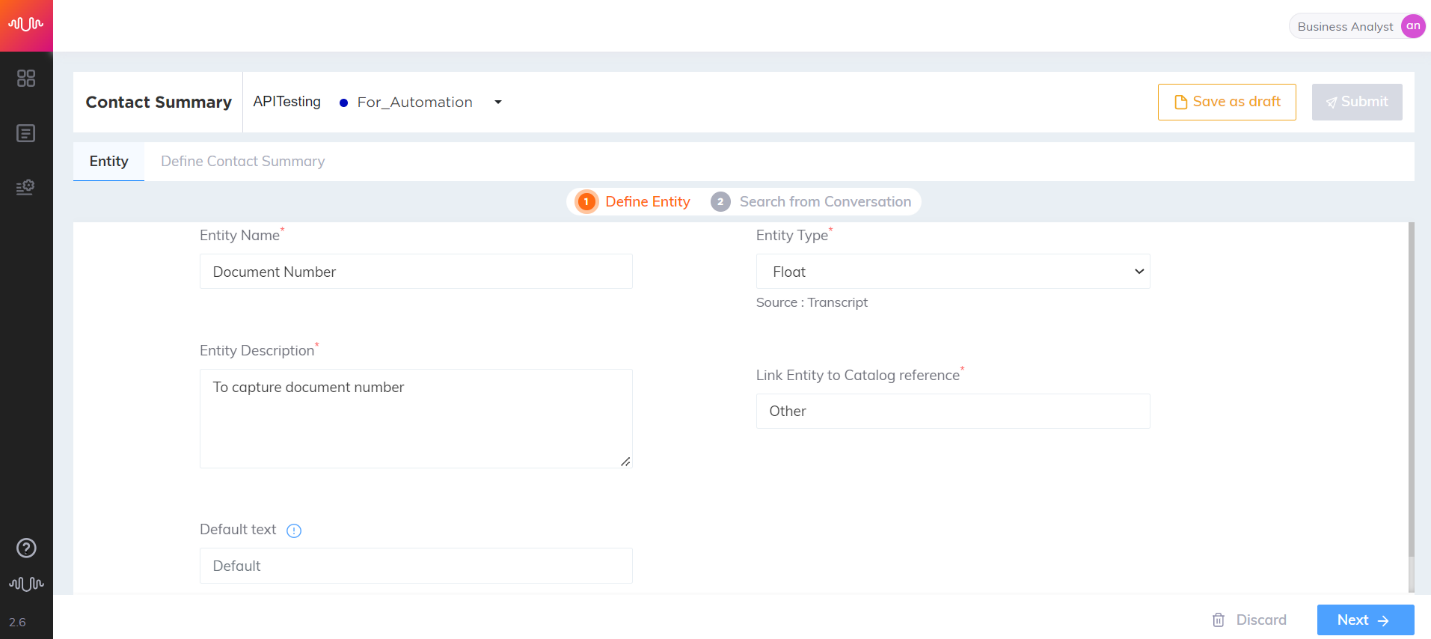 |
Best Practice:
Use a float and not number when decimal points are always discussed.
Use a float and not money when you have to extract a currency amount, when there is a possibility that the unit may not be discussed in the turn.
Free Form Entity
Entity which returns a string which is either a suffix or a prefix to a configured key word.
Telecom use case
Transcript:
Customer: I'm calling because my internet has stopped working since Nine pm last night.
Agent: Apologies for the inconvenience ma’am. Let me help you resolve the issue.
Entity configuration:
Entity Name: Issue
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Customer channel is “checked”
Entity Extraction Channel: Customer channel is “checked”
Key Phrases added are: “i'm calling because”, “the issue is”, “my problem is”
Entity Value: “internet has stopped working since 9pm last night.”
 |
Best Practice: We need to leverage AI intent model instead of Free Form Entity type.
Location Entity
Entity which is a geopolitical entity, i.e. countries, states, cities.
Utilities use case
Transcript:
Customer: I am calling you because I am shifting from Gujarat to Karnataka and hence, I would like to disconnect my gas connection.
Agent: Sure sir. Let me help you with that.
Entity configuration:
Entity Name: From Location
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Customer channel is “checked”
Entity Extraction Channel: Customer channel is “checked”
Key Phrases added are: “shifting”, “relocating”, “moving”
Entity Value: Karnataka
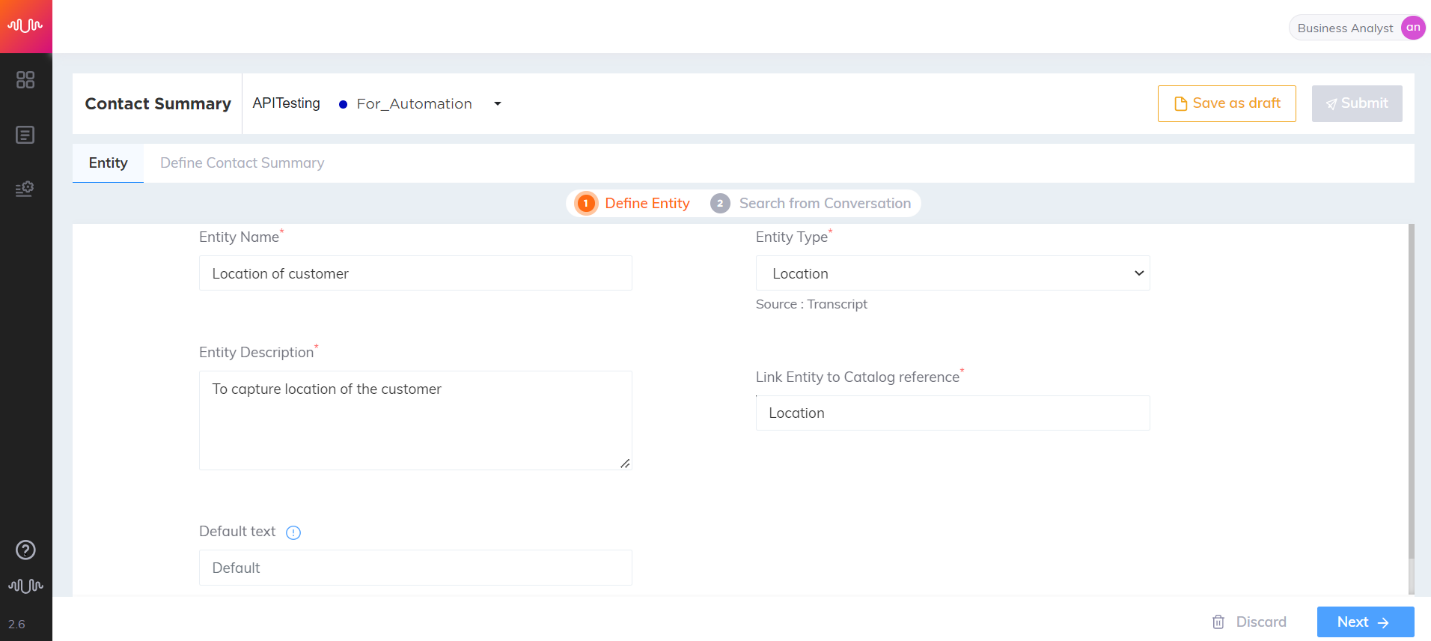 |
Best Practice: There may be many instances of the location, and it is the keyphrases that limit the false positives of a possible location hit. Hence, we need to be careful about the keyphrases configured.
Money Entity
Entity which contains monetary values, including unit. This entity type currently supports US Dollars, Indian Rupees, Korean Von, Australian Dollar, British Pounds, Euros and Japanese Yen.
Healthcare use case
Transcript:
Agent: Can you please mention the claim amount for the claim that you have submitted?
Customer: It was three thousand four hundred and thirty-two dollars.
Entity configuration:
Entity Name: Claim Amount
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Agent channel is “checked”
Entity Extraction Channel: Customer channel is “checked”
Key Phrases added are: “claim amount”
Entity Value: 3432
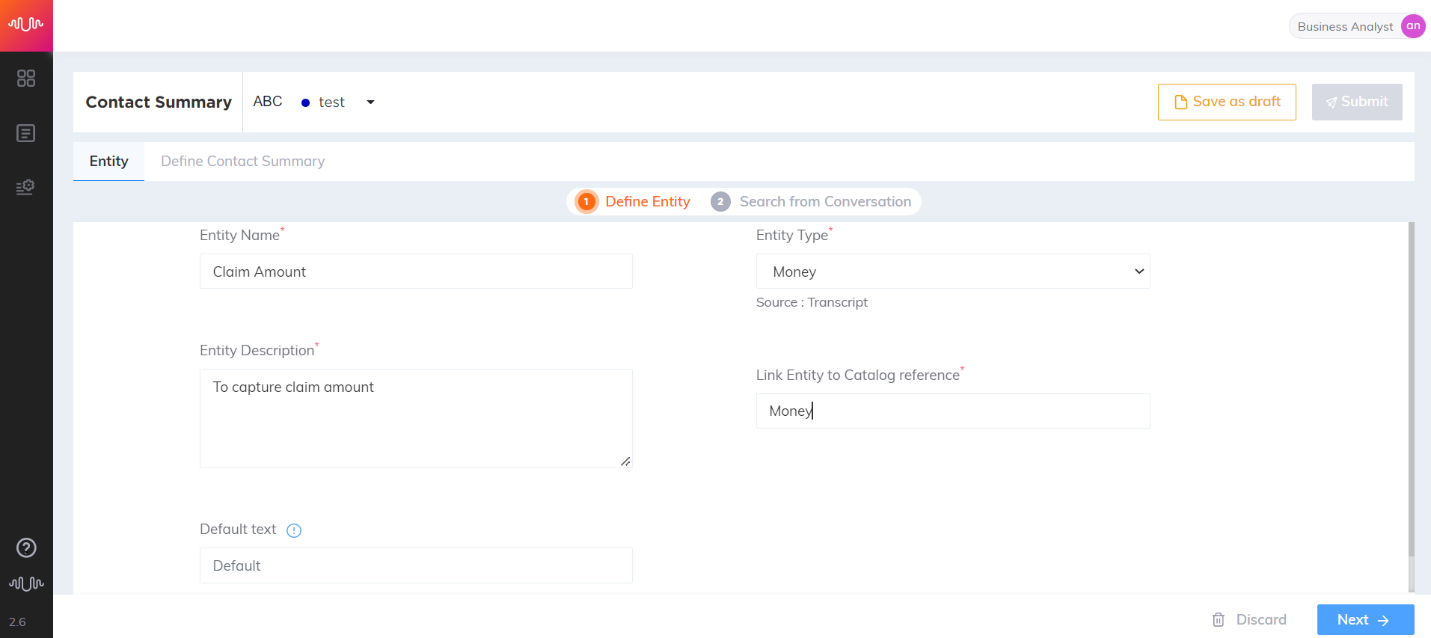 |
Best Practice: If the currency using is not spoken in the context then currency entity is not detected. Summaries should leverage rules where money and number entities are combined for such cases.
Organization Entity
Entity which contains the name(s) of companies, agencies or institutions.
Telecommunication use case
Transcript:
Customer : I am calling because your competing organization, Reliance Jio, is offering a plan of three nine nine rupees with much better benefits in comparison to the four nine nine plan that I have with you, and I wanted to check if you offer something similar.
Agent: Sorry sir, unfortunately we do not have such plans on offer.
Entity configuration:
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Agent and Customer channels are “checked”
Entity Extraction Channel: Agent channel is “checked”
Key Phrases added are: “Competing organization”, “Other operator”, “Competing operator”, “Other mobile company”
Entity Value: Reliance Jio
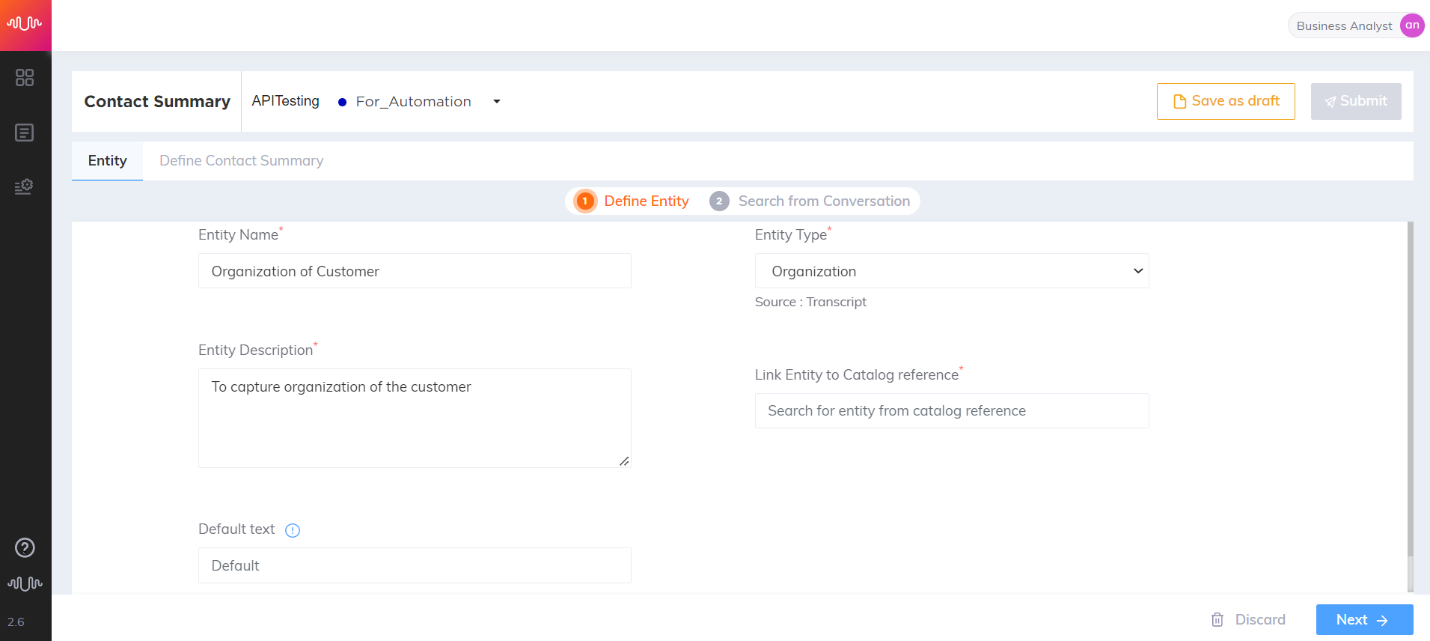 |
Best Practice: Accuracy can be improved when the NER model is trained with more data. Contact Uniphore team when accuracy is found to be low.
Percentage Entity
Entity which contains any values in percentages. Example: 50%, 60 percentage, etc.,
Healthcare use case
Transcript:
Customer: I would like to understand details of the copay amount regarding my insurance policy
Agent: Sure ma’am, I can help you with that. I see that the copay amount is twenty percent for your insurance policy.
Entity configuration:
Entity Name: Copay
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Agent and Customer channels are “checked”
Entity Extraction Channel: Agent channel is “checked”
Key Phrases added are: “copay” “copay percentage”
Entity Value: 20
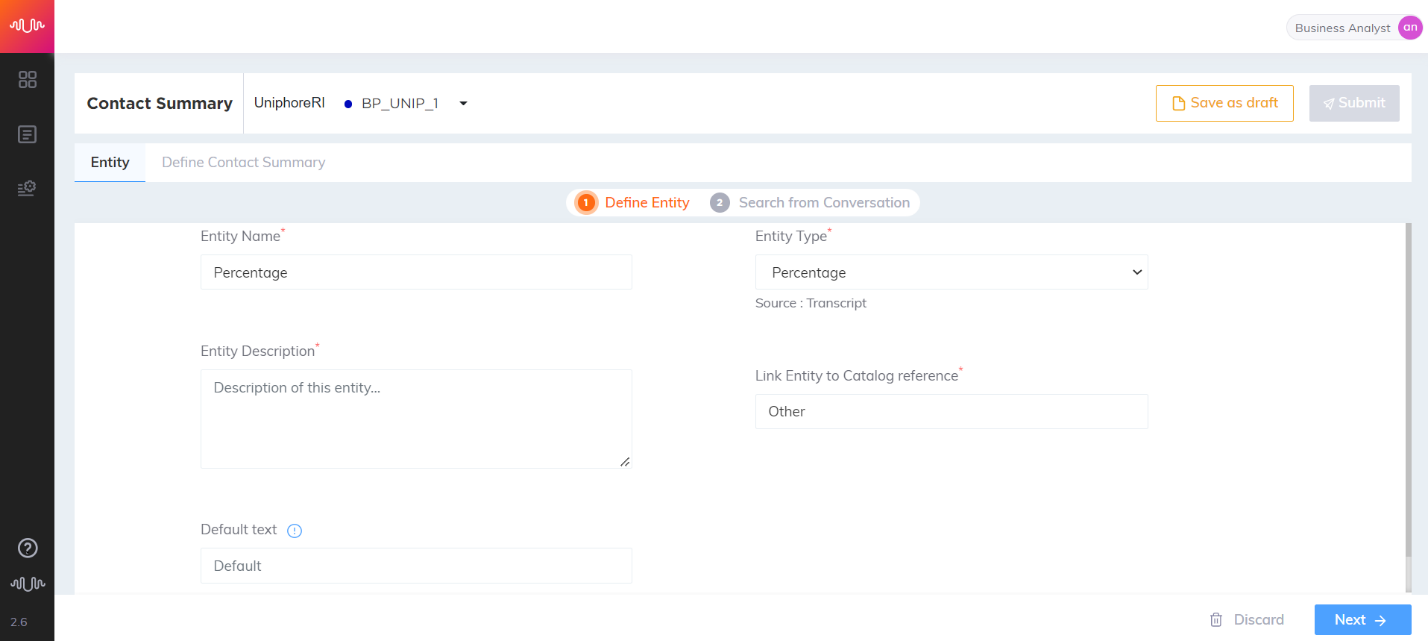 |
Person Entity
Entities which are names of people, including fictional names.
Generic use case
Transcript:
Customer: I am John Martins, and I am calling you about an issue which I raised with you last week.
Entity configuration:
Entity Name: Customer Name
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Customer channel is “checked”
Entity Extraction Channel: Customer channel is “checked”
Key Phrases added are: “I am” “my name is”
Entity Value: John Martins
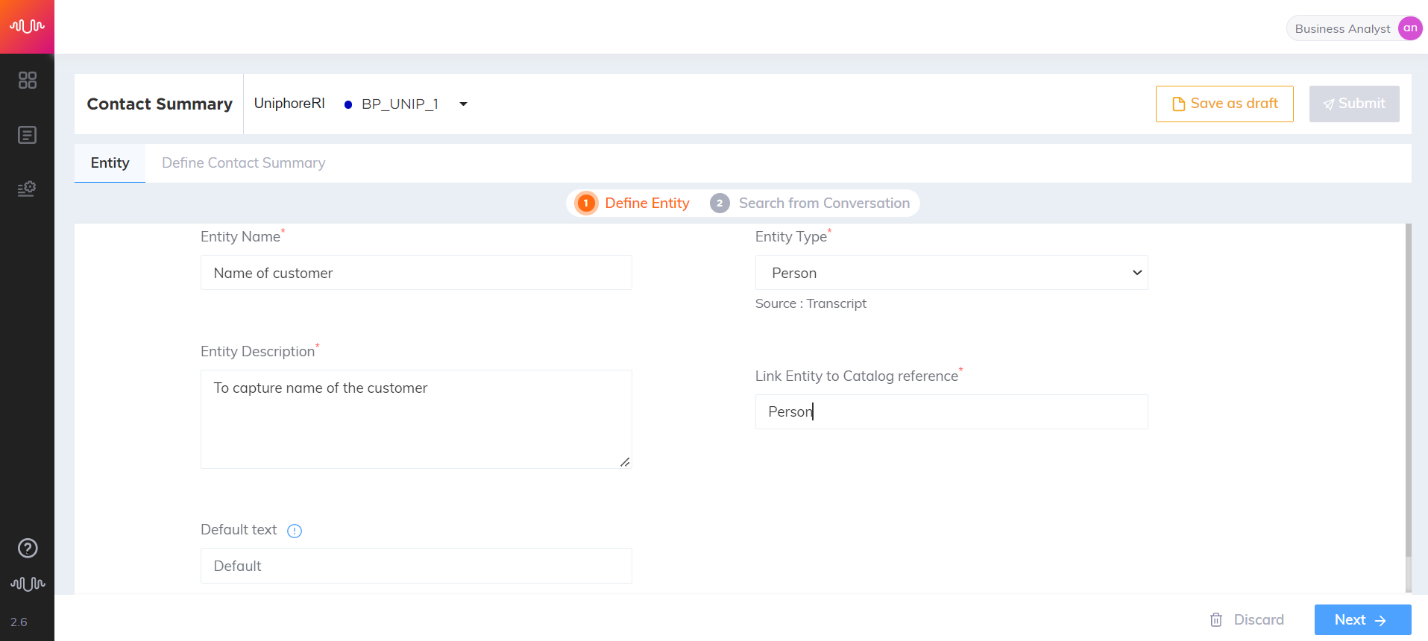 |
Best Practice: Accuracy can be improved when the NER model is trained with more data. Contact Uniphore team when accuracy is found to be low.
Relationship Entity
Entity which speaks of a relationship.
Example: father, spouse, friend, customer, manager, etc.,
Healthcare use case
Transcript:
Agent: May I know who is the primary insured member of the insurance policy?
Customer: I am the primary member.
Agent: And who is this insurance claim for? You or your dependent?
Customer: It’s for my son
Entity configuration:
Entity Name: Dependent
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Agent channel is “checked”
Entity Extraction Channel: Customer channel is “checked”
Key Phrases added are: “insurance claim” “dependent”
Entity Value: Son
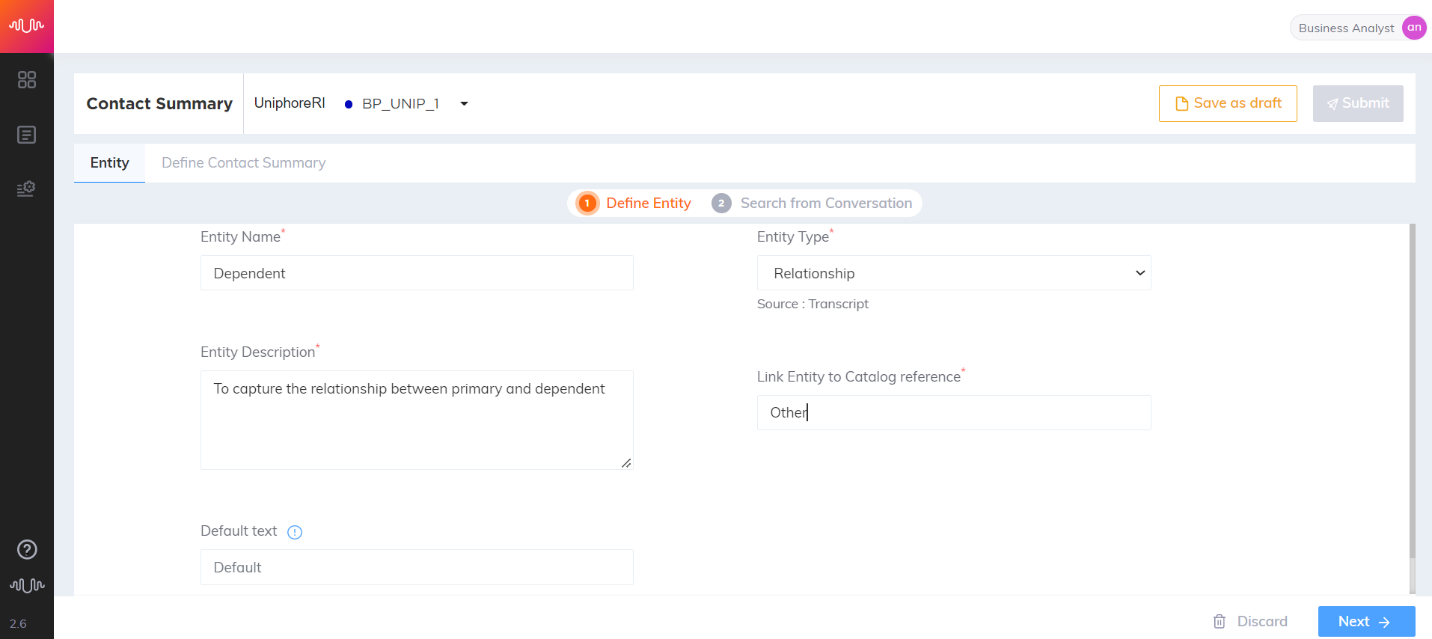 |
String Entity
Entity which returns a string with a match to configured keywords.
Retail use case
Transcript:
Agent: Can you please tell me if you are calling me for Televisions or Mobiles or Tablets?
Customer: I am calling regarding Tablets.
Entity configuration:
Entity Name: Device type
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Agent channel is “checked”
Entity Extraction Channel: Customer channel is “checked”
Key Phrases added are: “Televisions” “Television” “Mobiles” “Mobile” ”Tablets” “Tablet”
Entity Value: Tablets
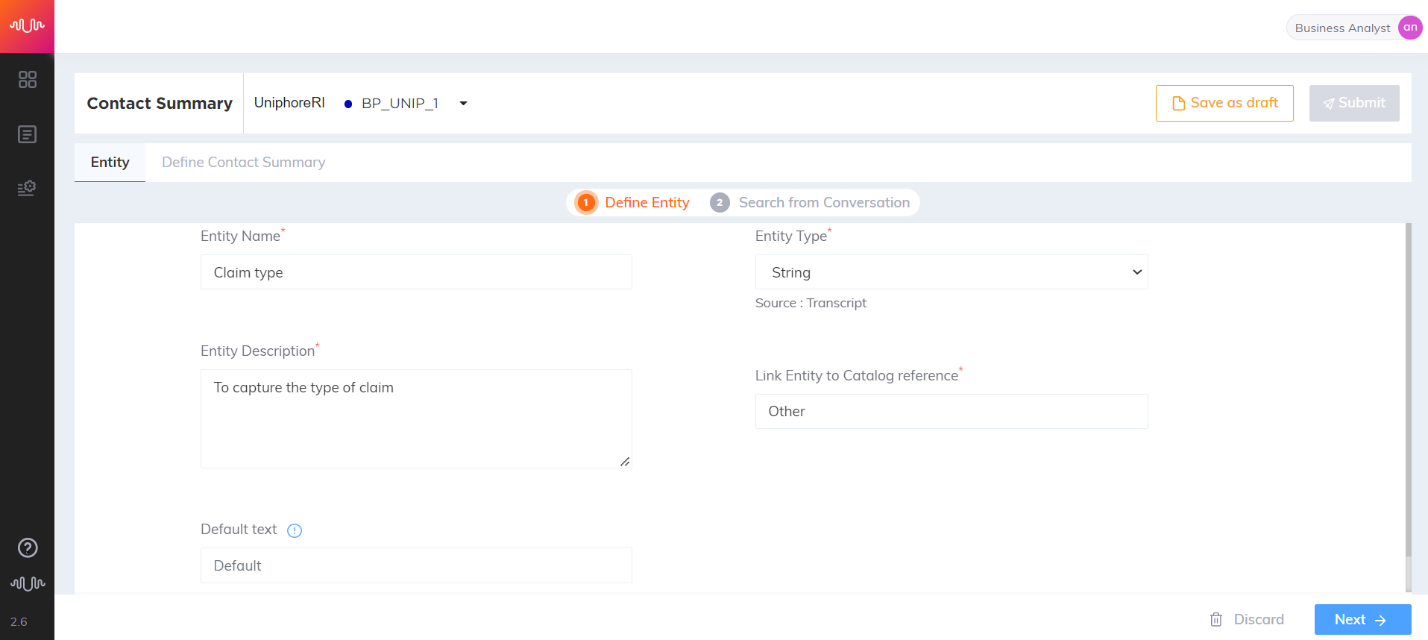 |
Best Practice:
Fuzzy match will not work fully
Avoid using a lot of string entities. It leads to performance degradation of Summary generation. It is recommended to use AI entities for these use cases.
Confirmation Entity
Entity that contains speaker affirmation based on the key words like yes, yeah, okay, no, I don’t want to, etc.
BFSI use case
Transcript:
Agent: Are you interested in this life time free credit card
Customer: Nope, I am not interested.
Entity configuration:
Name: Life-time free card
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Agent and Customer channels are “checked”
Entity Extraction Channel: Customer channel is “checked”
Key Phrases added are: “life time free” “credit card”
Entity Value: Nope
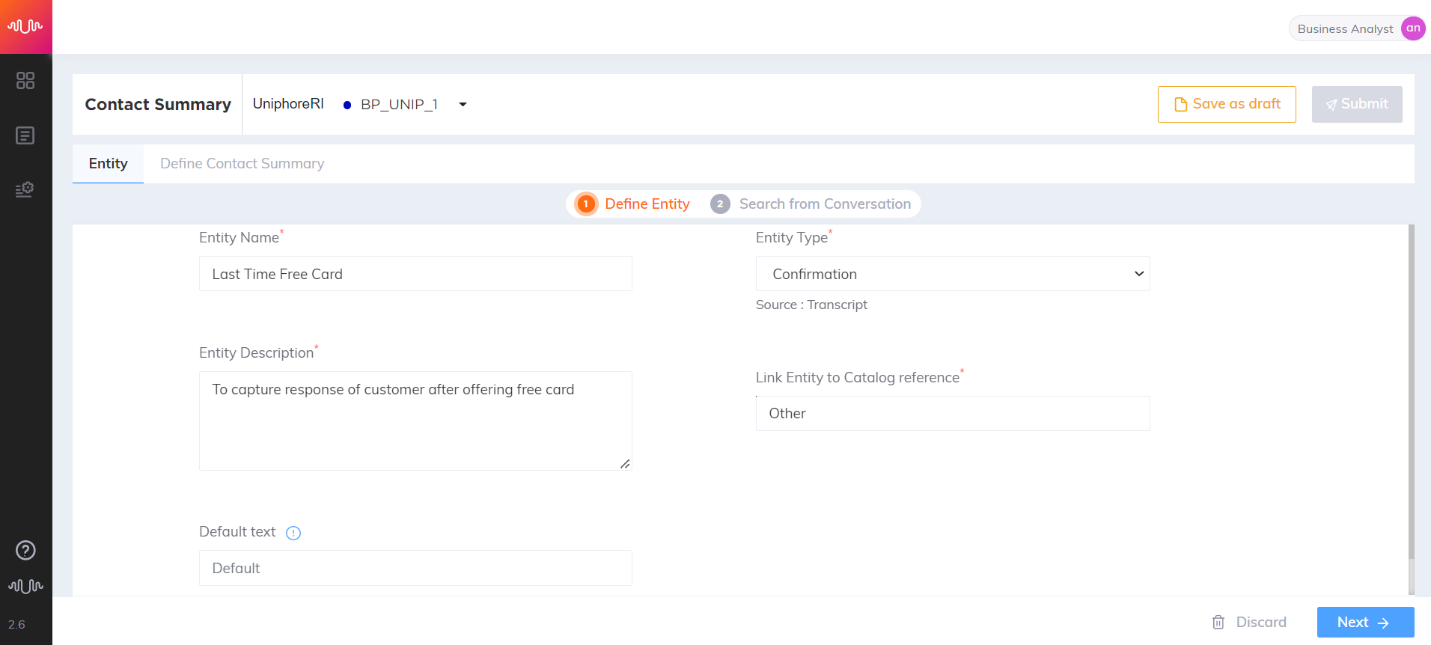 |
Interesting Fact: This is different from Boolean entity. This purely captures what was confirmed (Yes / No) by the other speaker.
Time Entity
Entity that contains a time reading.
Telecom use case
Transcript:
Agent: We have identified that there is probably an issue with your modem. I have scheduled for an appointment to have one of our technicians visit your house and rectify the issue on Friday, the twenty fifth of September at three pm. Is there anything else that I can assist you with?
Customer: Nothing else. I am good
Entity configuration:
Entity Name: Appointment Time
Entity Position: Prefix and Suffix “checked”
Key-Phrase Matching Channels: Agent channel is “checked”
Entity Extraction Channel: Agent channel is “checked”
Key Phrases added are: “appointment”, “scheduled”
Entity Value: 3pm
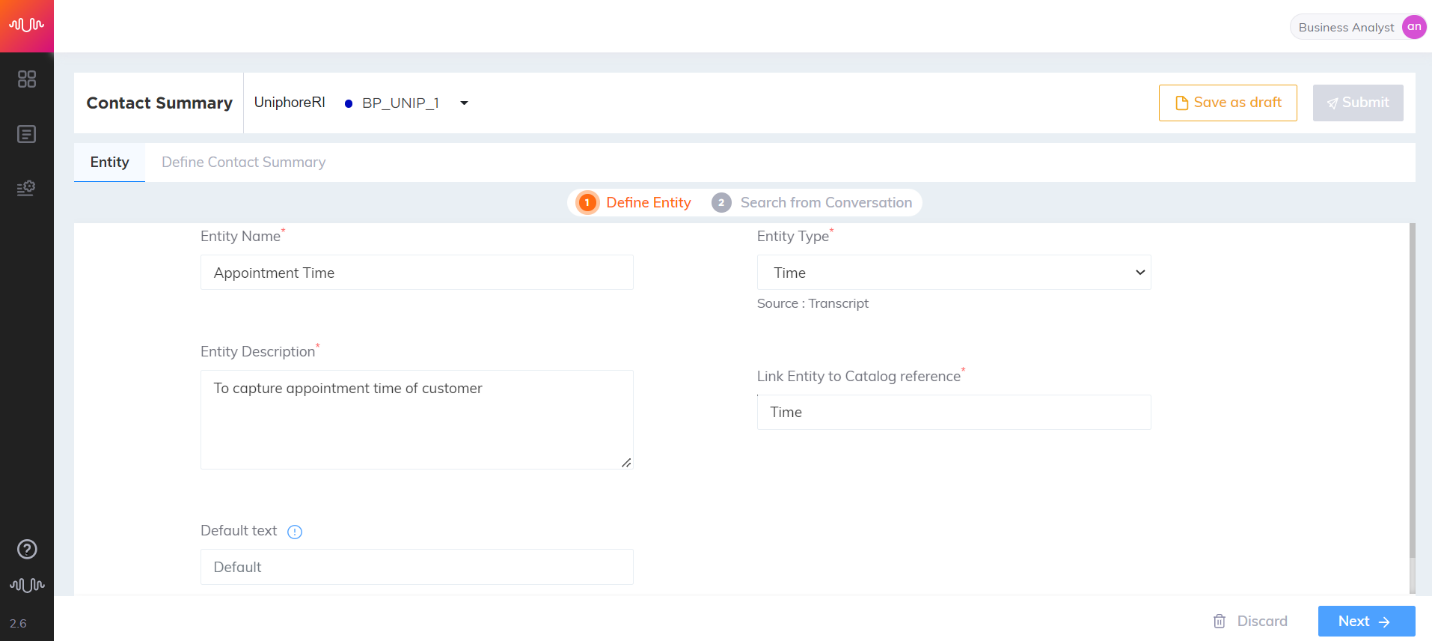 |
Best Practice:
It is recommended to customers about training agents in such a way that dates and times are always spoken by agents in a prescribed structure for good accuracy in model detection.
Website Entity
Entity which contains a website or web address. This Entity type helps to extract website domain names from transcripts using a basic website pattern.
Example: google.com, wikipedia.org, www.google.com, www.facebook.com
Generic use case
Transcript:
Customer: Hi, I want to know if you have any special promotions on your website right now.
Agent: Sure! We currently have a promotion for 20% off on all items if you order through our website.
Customer: How do I apply the discount?
Agent: You can use the promo code "SAVE20" at checkout. Just visit our website at www.abcproducts.com to place your order.
Entity configuration:
Name: Website
Entity Position: Both Prefix and Suffix
Keyword Matching Channel: Both Agent and Customer
Entity Extraction Channel: Customer
Configure Keywords: “website” “web address” etc.,
Entity Value: www.abcproducts.com
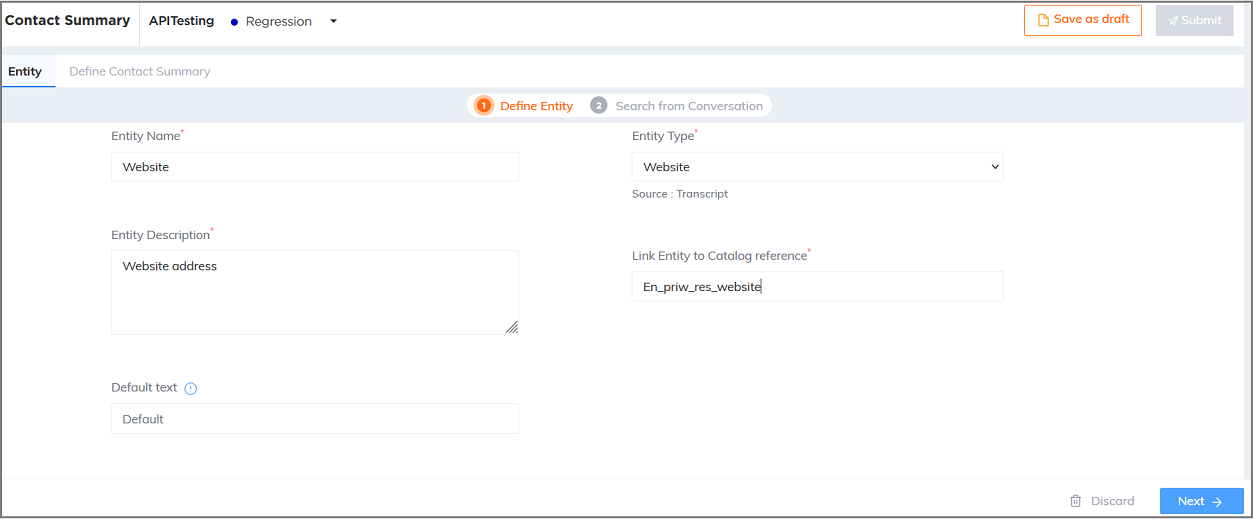
Copy Keyphrases from other Entities
Analyst can search for key phrases from other Entities and copy them to the current entity.
Click Copy Phrases from other Entities link.
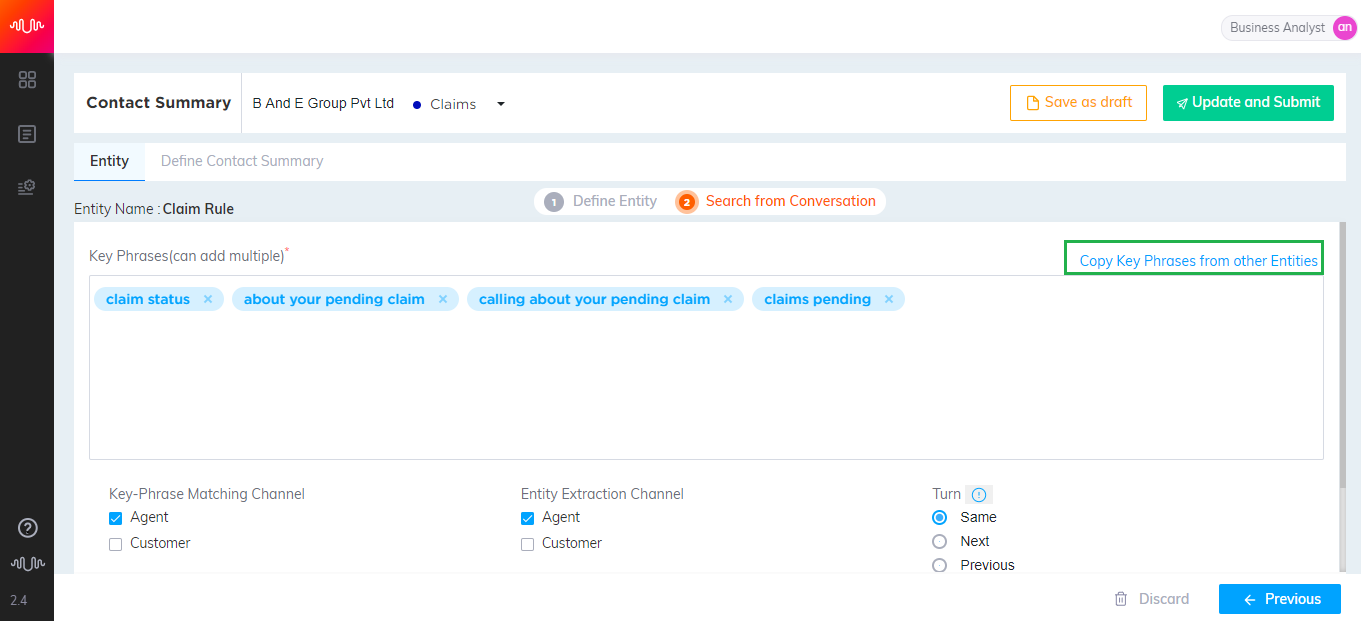
In the Search field, enter 3 characters to search for a keyphrase.
Select the keyphrase from the list. The selected keyphrase will be listed at the bottom of the pop-up window.
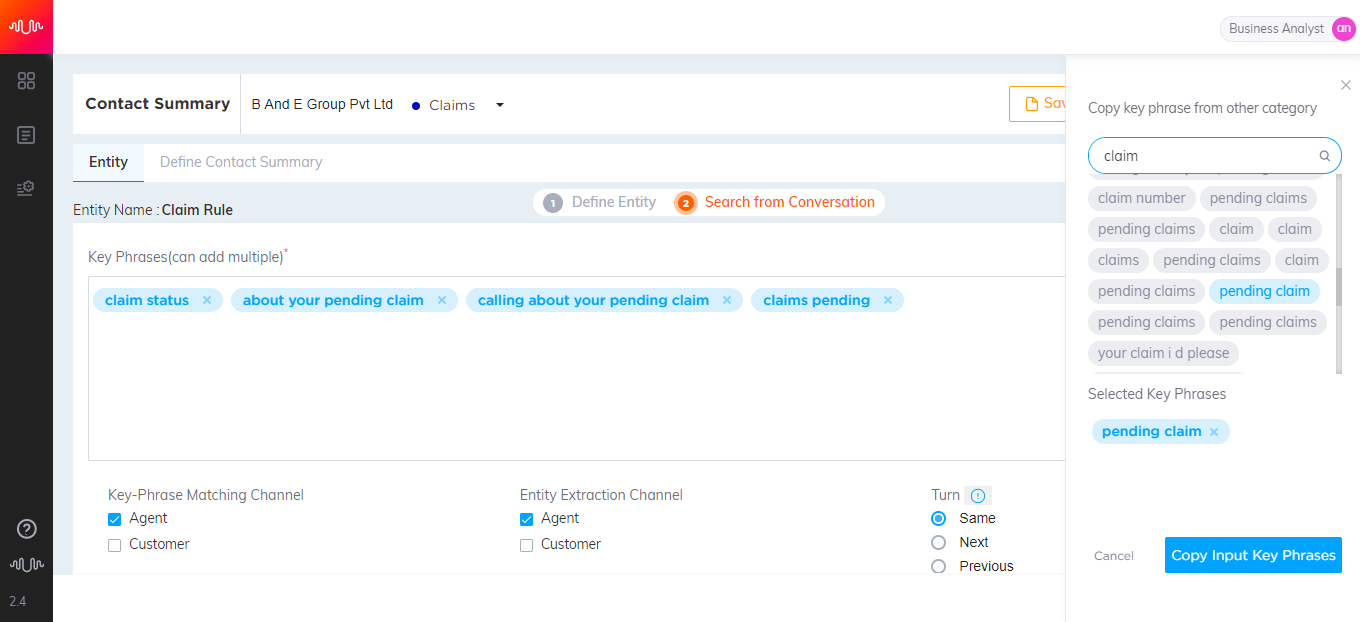
Click Copy Input Keyphrases button to copy the keyphrases from other entities and display in the Keyphrase section.
Complex Entity
Complex entities use REST APIs to retrieve data from various data sources like external CRM systems, other databases, and external APIs.
These entities are excluded in training the NLP models
These entities are excluded from the summary template and used only in rules
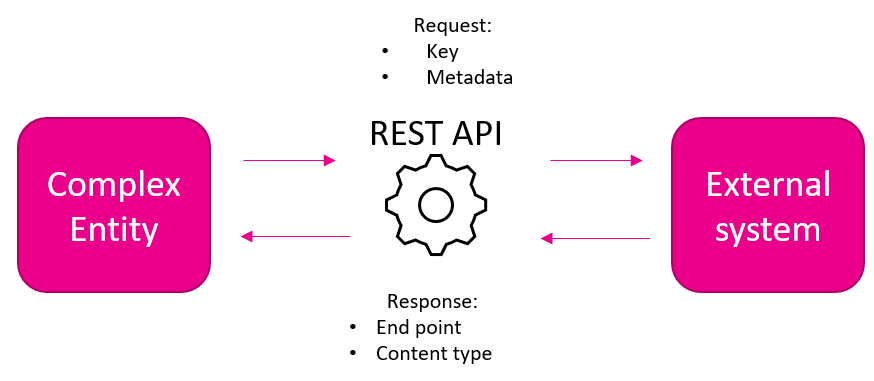 |
In complex entities, we can also pass AI entities in addition to NLP entities for sending as rest API arguments to external systems.
While exporting complex entities and rule entities including nested AI entities, the application provides a warning message indicating that AI entities have to be imported first in the target environment for a successful import.
The steps to define complex entity are listed below:
Select Organization from the drop-down list.
Select Business Process from the drop-down list.
Enter meta data of the intent in the Entity Name field.
Enter the description for meta data of the intent in the Description field.
Select Entity Type as 'Complex' from the drop-down list.
Click Next button to navigate to Map API screen.
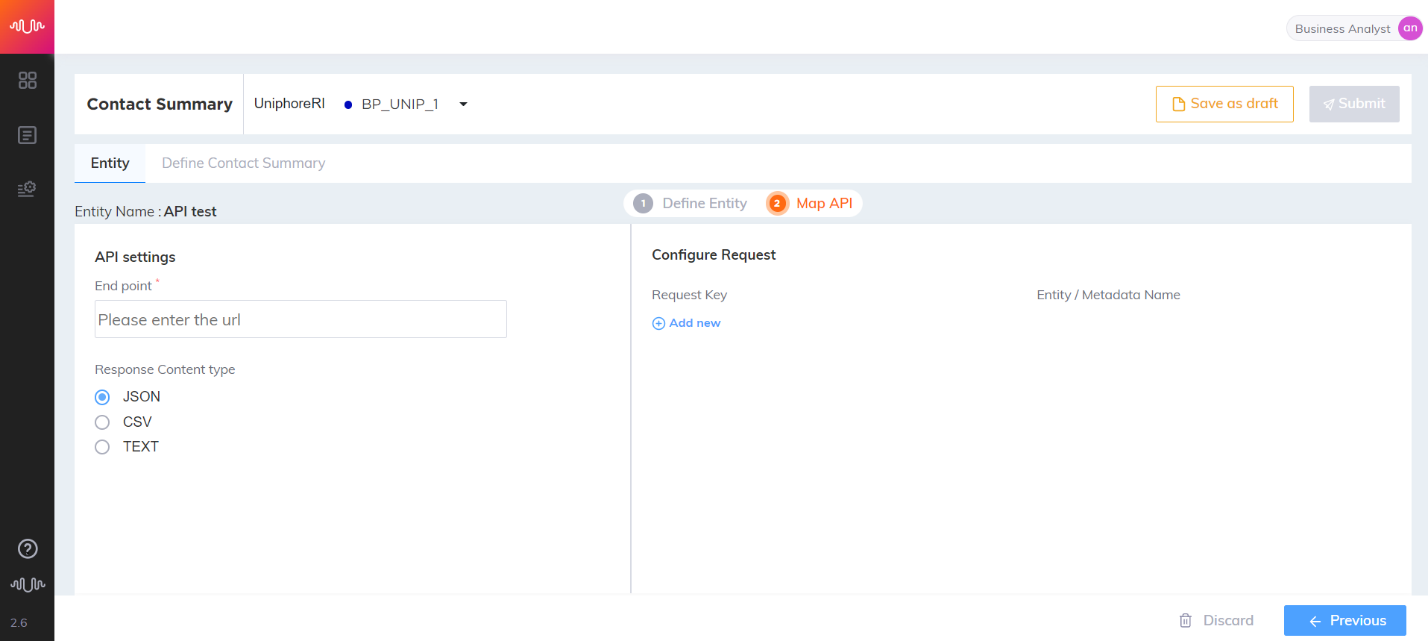
Complex Entity - Map API
On the left hand side, mention a valid URL in the Endpoint field. The URL should start with "http" or "https".
Note
Only the GET method is used in this configuration. Path variables are not supported.
Select a Context Response Type - JSON, CSV or Text.
On the right hand side, you are required to configure the request.
Type in a Request Key as a request parameter in the Request Key field.
Select the name of an entity or a metadata parameter from the "Entity / Metadata Name"drop-down field.
For every new request parameter, click the "Add New" button to add a row.
After configuration, click either "Save as Draft" or "Submit". You can also go back to the previous screen using "Previous" or discard the entity using the "Discard" button.
Validations
Before you configure a Complex entity, the following checks need to be performed on the client-side as well as the server-side.
Entity name should be unique
Endpoint should be a valid URL and should start with "http" or "https"
There should be one or more GET method query parameters, and each name should be the unique and valid without any spaces and special characters.
Examples
GET Method
Request
Name | Description |
|---|---|
Endpoint | Endpoint URL http://<host>:<port>/<path> |
Content-Type | application/json |
Query Parameters | One or more parameters id=1025¶m2=value2 |
curl -H 'Content-Type: application/json' --request GET 'http://<host>:<port>/member-info?id=1025¶m2=value2'Response
Content Type | HTTP Status | Response Body |
|---|---|---|
application/json | 200 | { "result": { "attr1": "value-1", "attr2": "value-2", "attr3": "value-3" }} |
3xx, 4xx, 5xx codes | { "errors": [ { "code": 1001, "message": "Member not found" }, { "code": 1002, "message": "Member id is invalid" } ]} |
There can be one or more error codes depending on the specific implementation of API.
Rules Configuration
The complex entities can be referenced in rules configuration. The following is the syntax used to refer the complex entities.
Syntax | Description |
|---|---|
$.complex('entity-name', 'json-path/column-name') | Reads a given column/attribute/path from the connector response. |
$.complex('entity-name', 'json-path/column-name', 'index-type') | Reads given column/attribute/path with index type (all, first or last) from the connector response. If the given column/attribute/path not found returns empty. Allowed index types are:
|
The rule engine has also been enhanced to invoke and consume the response from a complex entity response, based on the content type:
JSON (application/json) - Extract the desired attributes
CSV (text/csv) - Extract the desired columns
Text (text/plain) - Entire data
Define Rule Entity
A "Rule" entity type allows a Business Analyst to create an entity based on the output of a rule engine. A rule is a set of conditions applied on NLP entities, AI entities, Complex entities or other Rule entities. When the condition is satisfied, then the configured output is calculated as the output of the rule entity. This evaluated rule entity value is used in the contact summary. The rule entities are used for the following use cases:
Summary template based on conditions
Synthesize entity value based on conditions
Call resolution based on conditions
Prioritize entities
If two or more entities have to be sorted in any manner in order to extract one value
Usage of Negative phrases
Tokenizing native entities
Best practice:
Before each rule is created, we need to think twice if it is absolutely required. Accuracy improvement and tuning is much easier and cleaner when entities defined independently are used in summaries.
Following are the steps to define a rule entity:
Select Organization from the drop-down list.
Select Business Process from the drop-down list.
In the Entity Name field, mention the name of entity.
In the Entity Description field, mention the entity description.
In the Default text field, mention the default value to be shown in the summary if the entity does not trigger any values.
From the Entity Type drop-down, select the entity type as "Rule".
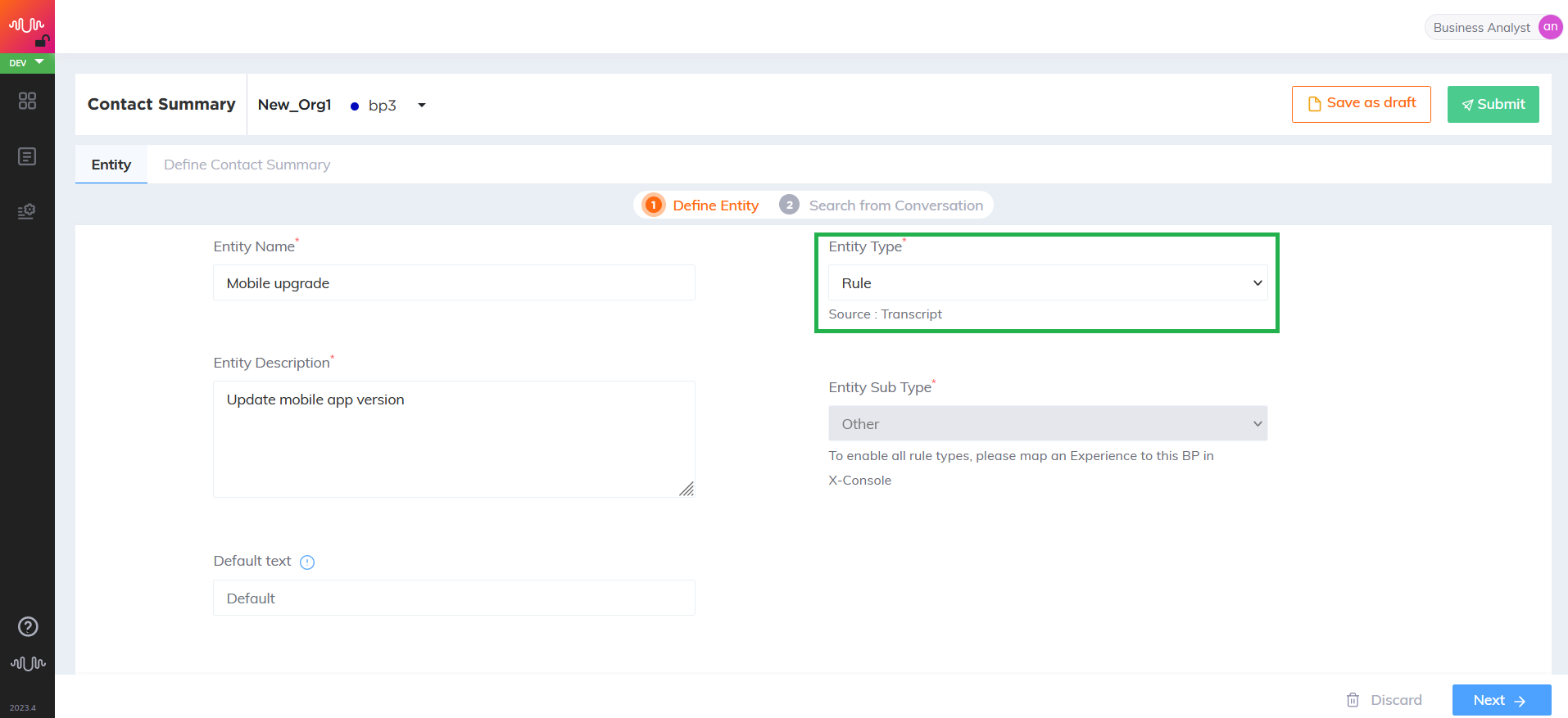
To enable Entity Sub Type drop-down, map an Experience to this Business Process in X-Console. For mapping of Experience to the Business Process, click here.
If the mapping is not done, the rule is automatically categorized as “Other” type. This drop-down is only available for Rule entity type.
Note
The rules which are already existing in the system are automatically assigned to the rule type “Other” after upgrading U-Assist application to the version 23.4.1.
Any previous version's JSON file containing the rule entities can be successfully imported into this version 23.4.1 with the rule type 'Other'.
After mapping the experience to the Business Process, the Business Analyst has an option to select any one of the below rule types from the Entity Sub Type drop-down list:

Call reason - Enables Analyst to define a rule with the 'Call reason' type. After syncing the U-Assist account with the AI Model, the rule categorized as "Call reason" is displayed on the X‑Console Intents list. If the rule is triggered, the name of the rule is displayed as the intent name on the X‑Console Agent Application. For more details on defining the call reason rule, click here.
The rule written with complex entities must have the Sub Type 'Other'. Complex entities are not processed (as conditions or outputs) in rules with Sub Type 'Call reason'.
Any rule nested with complex rule must have the Sub Type 'Other'.
Important
In the X‑Console's Intents page, only the rule-based intents 'Call reason' that are in the trained status are listed.
In X-Console, a Flow Admin can define the call summary template to be displayed in real time to an agent during a call for the rule-based intent and also assign a flow which is to be triggered when this Intent is identified by U-Assist.
For more details on creating an intent summary template, click here.
Note
The rule-based intents 'Call reason' are not displayed in the Intents page of the Experience.
Other - Enables Analyst to configure the rule in any way. However, this type of rule does not appear in the Intents list on X‑Console.
Click Next to navigate to the Search from Conversation page.
The default entity name is displayed at the top of the page. Mention input parameters in JSON format in Rule Definition section. Every rule can have multiple rule components. Each component can be defined as a rule.
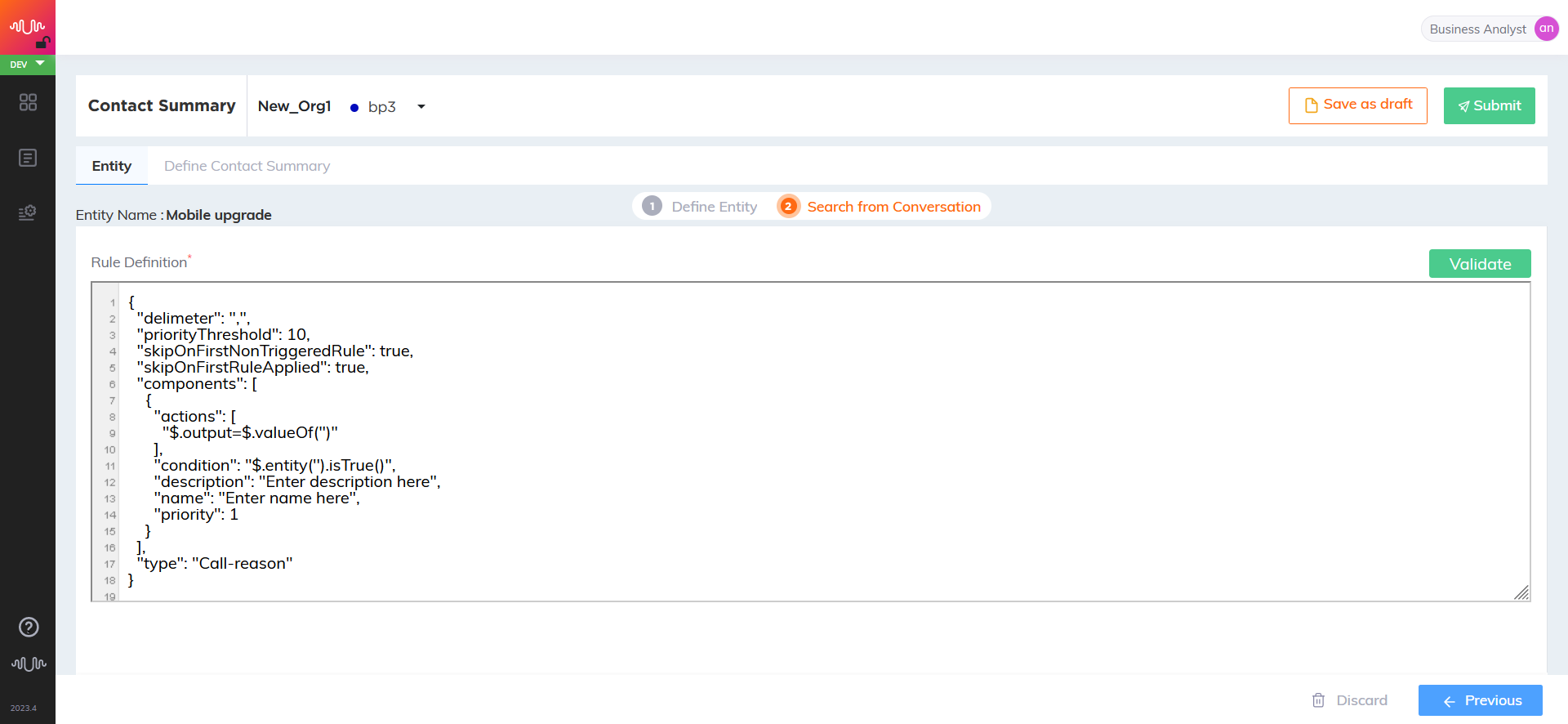
Call reason rule definition
If a "Call reason" rule has different output values in different components, the intent name on X‑Console is always be the overall rule name (i.e., a single rule can not provide multiple intents). For each intent that needs to be detected, the Business Analyst must write a separate rule.
For example, in the below given rule, the name of the rule intent is displayed as "Customer request" on X‑Console:
{ "type": "Call-reason", "id": 0, "ruleName": "Customer request", "skipOnFirstRuleApplied": false, "skipOnFirstNonTriggeredRule": false, "priorityThreshold": 100, "delimeter": ",", "components": [ { "name": "Canceled Line or Account", "description": "Canceled Line or Account - Customer Request", "priority": 1, "condition": "$.entity('cancel_line').isTrue()", "actions": [ "$.output='Canceled Line'" ] }, { "name": "Account Number Provided", "description": "Account Number Provided", "priority": 2, "condition": "$.entity('acct_number').isTrue()", "actions": [ "$.output='Account Number Provided'" ] }, { "name": "Device - IMEI/SIM Updated", "description": "Device - IMEI/SIM Updated", "priority": 3, "condition": "$.entity('sim_updated').isTrue()", "actions": [ "$.output='Device - IMEI/SIM Updated'" ] }, { "name": "Restore from Suspend - Customer Request", "description": "Restore from Suspend - Customer Request", "priority": 5, "condition": "$.entity('restore_from_suspend').isTrue()", "actions": [ "$.output= 'Restore from Suspend - Customer Request'" ] }, ] }, "apiConfig": null, "nestedEntities": [ "cancel_line", "acct_number", "sim_updated", "restore_from_suspend", ] }Click Validate to validate the rules.
{ "delimeter": ",", "priorityThreshold": 10, "skipOnFirstNonTriggeredRule": true, "skipOnFirstRuleApplied": true, "components": [{ "actions": [ "$.output=$.valueOf('<entity name>')" ], "condition": "$.entity('<entity name>').isTrue()", "description": "Enter description here", "name": "Enter name here", "priority": 1 } ], "type": "Call-reason" }After validating the rules, click Submit. The newly created entity is listed in the Entity page. A confirmation message is displayed as shown below, after submitting the entity.
Based on the requirements, select any of the below options:
Go to Entity List - To navigate to the Entity List page.
Create New - To create a new entity.
Train Entity - To train the newly created entity.
Structure of JSON Rule
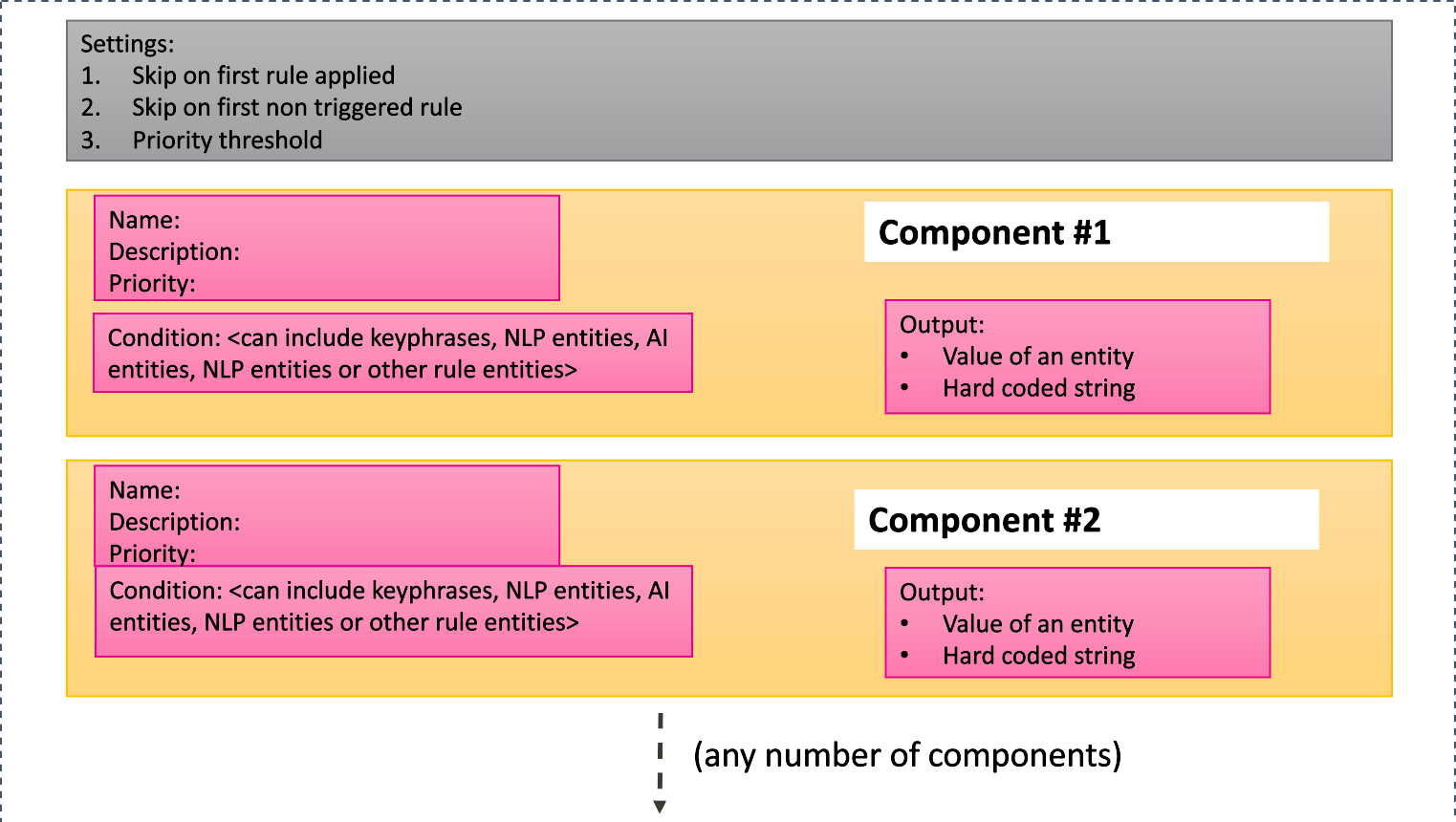 |
Parameters | Parameter Values | Data Types |
delimeter | Symbol used as a boundary between multiple rule conditions output. It is used to concatenate multiple component outputs. | String |
priorityThreshold | Positive integer. Stop evaluation of the rules, if rule priority exceeds the defined threshold. | Integer |
skipOnFirstNonTriggeredRule | When any rule component evaluates to false, skip evaluation of rest of the components | Boolean (True / False) |
skipOnFirstAppliedRule | When any one of the components is evaluated to true, then skip evaluation of further rule components | Boolean (True) |
components | Part of a rule which includes a condition and an output. Sample JSON. [{ "actions": [ "$.output=$.valueOf(' ')" ], "condition": "$.entity(' ').isTrue()", "description": "Enter description here", "name": "Enter name here", "priority": 1 } ] } | JSON array of objects |
actions | A set of actions to be performed when the conditions are satisfied. | String |
condition | A set of conditions to be applied for a rule. Rule condition must result either in True or False. | String |
description | Description of rule component. | String |
name | Name of the rule component. It must be unique for each rule component. | String |
priority | Rule component priority. It must start from 1. For each rule component, priority is increased by one. | Integer |
type | Type of rules. | String |
Best practices:
Skip rule computation wherever possible using skiponfirstruleapplied and skiponfirstruletriggered
Use rules only where necessary. Avoid large number of components
After import from another environment, ensure to re-train all entities.
Refer to the page "Create rules with different conditions" for rule input.
Rules can also be written using AI entities in addition to rules on NLP and complex entities which were earlier supported. A subset of the functions supported for NLP entities can also be supported for AI entities.
Refer to the page "Rule Configuration for AI entities" for configuration of different conditions and outputs.
Create rules with different conditions
Analyst can define set of conditions and corresponding actions. The evaluated end result of the rule can then be used to publish the Contact Summary.
Given below are some examples of conditions and their corresponding rule inputs:
String Search
Rule with 'containsAnyKeyPhrases' and logical operator 'AND'
The given rule condition evaluates to true, when any of the input key phrases is detected in the turn(s) where the entity/entities was/were detected and the applied conditions are satisfied.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue').containsAnyKeyPhrases('How may I help you', 'This problem is still not resolved').isTrue() && $.entity('Customer Name').isTrue()",
"actions": [
"$.output=$.value()"
]
}
]
}
Rule with 'containsAllKeyPhrases'
The given rule condition evaluates to true, when all the input key phrases are detected in the turn transcript.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue').containsAllKeyPhrases('How may I help you', 'This problem is still not resolved', 'didn't get a message').isTrue()",
"actions": [
"$.output=$.value()"
]
}
]
}
Rule with 'containsAllKeyPhrases' and 'minOccurs'
This rule condition evaluates to true, when all the input key phrases are detected in the turn transcript and the number of occurrences of these key phrases is greater than or equal to the minimum occurrence value.
In the below example, both the key phrases 'How May I help you', 'I have an issue' should have at least 3 occurrences in the turn transcripts from the NLP output.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue').containsAllKeyPhrases('How may I help you', ‘I have an issue').minOccurs(3).isTrue()",
"actions": [
"$.output=$.firstValue()"
]
}
]
}
Rule with 'containsAnyKeyPhrases' and 'minOccurs'
This rule condition evaluates to true, when any of the input key phrases are detected in the turn transcript and the number of occurrences of these key phrases are greater than or equal to the minimum occurrence value.
In the below example, any of the key phrases 'How May I help you', 'I have an issue' should have at least 3 occurrences in the turn transcripts from the NLP output.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue').containsAnyKeyPhrases('How may I help you', 'I have an issue').minOccurs(3).isTrue()",
"actions": [
"$.output=$.firstValue()"
]
}
]
}
Rule with 'containsAllKeyPhrases' and 'maxOccurs'
This rule condition evaluates to true, when all the input key phrases are detected in the turn transcript and the number of occurrences of these key phrases are lesser than or equal to the maximum occurrence value.
In the below example, both the key phrases 'How May I help you', 'I have an issue' should have at most 3 occurrences in the turn transcripts from the NLP output.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue').containsAllKeyPhrases('How may I help you', 'I have an issue').maxOccurs(3).isTrue()",
"actions": [
"$.output=$.firstValue()"
]
}
]
}
Rule with 'containsAnyKeyPhrases' and 'maxOccurs'
This rule condition evaluates to true, when any of the input key phrases are detected in the turn transcript and the number of occurrences of these key phrases are lesser than or equal to the maximum occurrence value.
In the below example, any of the key phrases ‘How May I help you', 'I have an issue' should have at most 3 occurrences in the turn transcripts from the NLP output.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue').containsAnyKeyPhrases('How may I help you', 'I have an issue').maxOccurs(3).isTrue()",
"actions": [
"$.output=$.firstValue()"
]
}
]
}
String Search - Regex
Rule with containsAllRegexKeyPhrases and max occurs
This rule condition evaluates to true, when all the input key phrases are detected in the turn transcript and the number of occurrences of these key phrases are lesser than or equal to the maximum occurrence value.
In the below example, both the key phrases 'How May I help you', 'I have an issue' should have at most 3 occurrences in the turn transcripts from the NLP output.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue'). containsAllRegexKeyPhrases('How may I help you', 'I have an issue').maxOccurs(3).isTrue()",
"actions": [
"$.output=$.firstValue()"
]
}
]
}
Rule with 'containsAnyRegexKeyPhrases' and 'maxOccurs'
This rule condition evaluates to true, when any of the input key phrases are detected in the turn transcript and the number of occurrences of these key phrases are lesser than or equal to the maximum occurrence value.
In the below example, any of the key phrases 'How May I help you', 'I have an issue' should have at most 3 occurrences in the turn transcripts from the NLP output.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue'). containsAnyRegexKeyPhrases('How may I help you', 'I have an issue').maxOccurs(3).isTrue()",
"actions": [
"$.output=$.firstValue()"
]
}
]
}
Rule with 'containsAllRegexKeyPhrases' and each 'maxOccurs'
This rule condition evaluates to true, when all the input key phrases are detected in the turn transcript and the number of occurrences of each of the key phrases is lesser than or equal to the maximum occurrence value.
In the below example, both the keyphrases 'How May I help you', 'I have an issue' should be detected in the turn transcript and each keyphrase occurrence count should be at most 3.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue'). containsAllRegexKeyPhrases('How may I help you', 'I have an issue').eachMaxOccurs(3).isTrue()",
"actions": [
"$.output=$.firstValue()"
]
}
]
}
Rule with 'containsAnyRegexKeyPhrases' and 'each max occurs'
This rule condition evaluates to true, when any of the input key phrases are detected in the turn transcript and the number of occurrences of detected key phrases is lesser than or equal to the maximum occurrence value.
In the below example, any of the keyphrases 'How May I.*', 'I have.*' should be detected in the turn transcript and detected keyphrase occurrence count should be at most 3.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue'). containsAnyRegexKeyPhrases('How may.*', 'I have.*').eachMaxOccurs(3).isTrue()",
"actions": [
"$.output=$.firstValue()"
]
}
]
}
Rule with 'containsAllRegexKeyPhrases' and 'each minOccurs'
This rule condition evaluates to true, when all the input key phrases are detected in the turn transcript and the number of occurrences of each of the key phrases is greater than or equal to the minimum occurrence value.
In the below example, all the keyphrases 'How May I.*', 'I have.*' should be detected in the turn transcript and each keyphrase occurrence count should be at least 3.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue'). containsAllRegexKeyPhrases('How may I.*', 'I have.*').eachMinOccurs(3).isTrue()",
"actions": [
"$.output=$.firstValue()"
]
}
]
}
Rule with 'containsAnyRegexKeyPhrases' and 'each min occurs'
This rule condition evaluates to true, when any of the input key phrases are detected in the turn transcript and the number of occurrences of detected key phrases is greater than or equal to the minimum occurrence value.
In the below example, any of the keyphrases 'How May I.*', 'I have.*' should be detected in the turn transcript and detected keyphrase occurrence count should be at least 3.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue'). containsAnyRegexKeyPhrases('How may.*', 'I have.*').eachMinOccurs(3).isTrue()",
"actions": [
"$.output=$.firstValue()"
]
}
]
}
Best Practice:
Regex functions are useful to handle multiple patterns in keywords.
Rules with different conditions
Rule with 'value' and 'contains'
Value can be used along with containsAllKeyPhrases, containsAnyKeyPhrases, minOccurs, maxOccurs, eachMinOccurs, eachMaxOccurs. It collects all the values of entity / entities used in the matched conditions. Values are separated by comma.
Contains will validate if the input is present in the extracted entities of the matched conditions.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue').containsAllKeyPhrases('How may I help you').value().contains('I have lost my card')",
"actions": [
"$.output=$.value()"
]
}
]
}
Rule with value and matches
Matches can have regex condition as an input.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [{
"name": "Complaint",
"description": "bill payment issue",
"priority": 1,
"condition": "$.entity('Customer Issue').containsAllKeyPhrases('How may I help you').value().matches('I have.*')",
"actions": [
"$.output=$.value()"
]
}
]
}
Rule with special ‘validate’ function for date entities
The date entity has a special validate function to check if the format and values of the date detected in the NLP layer is valid or not. i.e. if date is more than 31 or month more than 12 we have an issue.
 |
Best Practice: Leverage special functions like Date Validate function
Output value of Entity in Title Case
If the first name and last name detected have to be presented in title case, of capital letter in the summary, such functions can be leveraged
Rule with Case insensitive match against a string literal
If the entity value needs to be checked against a string literal without being worried about the case then equalsIgnoreCase which is one among the several possible string functions that can be used
Terminology Check-in
Contributed word: The key phrase that was used to detect the entity from the transcript. This is one of the key phrases that was used to configure the entity.
Phrase: Any one of the key phrases that are being used in the Rule
Entity value: The value of the extracted entity
Distance: Number of words separating two values in a turn
Best Practice:
Using Proximity functions as an alternate to capturing variations of Key phrases should be avoided
It drastically increases rule complexities and becomes very difficult to tune, manage and improve accuracy
Proximity Check: Contributed Word & Phrase
Rule with contributedWordAfterPhrase('distance','<Key-phrase>')
This rule condition evaluates to true, when the input key phrase is detected after the contributed word and within the given distance. Distance denotes number of words.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').contributedWordAfterPhrase('3','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with contributedWordAfterPhrase('distance','<Key-phrase>'); If the distance is not required then give -1
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').contributedWordAfterPhrase('-1','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with contributedWordBeforePhrase('distance','<Key-phrase>')
This rule condition evaluates to true, when the input key phrase is detected before the contributed word and within the given distance. Distance denotes number of words.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').contributedWordBeforePhrase('3','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with contributedWordBeforePhrase('distance','<Key-phrase>'); If the distance is not required then give -1
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').contributedWordBeforePhrase('-1 ','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Proximity Check: Phrase & Entity Value
Rule with phraseAfterEntityValue('distance','<Key-phrase>')
This rule condition evaluates to true, when the input key phrase is detected after the entity value and within the given distance. Distance denotes number of words.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').phraseAfterEntityValue('3','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with phraseAfterEntityValue('distance','<Key-phrase>'); If the distance is not required then give -1
This rule condition evaluates to true, when the input key phrase is detected after the entity value and within the given distance. Distance denotes number of words.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').phraseAfterEntityValue('-1 ','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with phraseBeforeEntityValue('distance','<Key-phrase>')
This rule condition evaluates to true, when the output key phrase is detected before entity value and within the given distance. Distance denotes number of words.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').phraseBeforeEntityValue('3','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with phraseBeforeEntityValue('distance','<Key-phrase>'); If the distance is not required then give -1
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').phraseBeforeEntityValue('-1 ','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Proximity Check: Phrase, Contributed Word & Entity Value
Rule with phraseBetweenContributedWordAndEntityValue('<Key-phrase>')
This rule condition evaluates to true, when the output key phrase is detected between the contributed word and the entity value.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit'). phraseBetweenContributedWordAndEntityValue('limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with phraseBetweenEntityValueAndContributedWord('<Key-phrase>')
This rule condition evaluates to true, when the output key phrase is detected between the entity value and contributed word.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').phraseBetweenEntityValueAndContributedWord('limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Proximity Check: Entity Value & Contributed Word
Rule with contributedWordAndEntityValueRange(distance)
This rule condition evaluates to true, when the output entity value is detected after contributed word within a specific distance as passed in the condition. Distance denotes number of words.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0",
"description": "string",
"priority": 1,
"condition": "$.entity('Plan Paid Amount').contributedWordAndEntityValueRange(1).isTrue()",
"actions": [
"$.output=$.value()"
]
}
]
}
Rule with entityValueAndContributedWordRange(distance)
This rule condition evaluates to true, when the output contributed word is detected after entity value within a specific distance as passed in the condition. Distance denotes number of words.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Plan Paid Amount').entityValueAndContributedWordRange(2).isTrue()",
"actions": [
"$.output=$.value()"
]
}
]
}
Proximity Check: Negative phrases
Rule with neContributedWordAfterPhrase('distance','<Key-phrase>')
This rule condition evaluates to true, when the input key phrase is not detected after the contributed word and not within the given distance. Distance denotes number of words.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').neContributedWordAfterPhrase('3','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with neContributedWordAfterPhrase('distance','<Key-phrase>'); If the distance is not required then give -1
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').neContributedWordAfterPhrase('-1','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with nePhraseAfterEntityValue('distance','<Key-phrase>')
This rule condition evaluates to true, when the input key phrase is not detected after the entity value and not within the given distance. Distance denotes number of words.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').nePhraseAfterEntityValue('-1 ','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with nePhraseAfterEntityValue('distance','<Key-phrase>'); If the distance is not required then give -1
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').nePhraseAfterEntityValue('-1 ','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with neContributedWordBeforePhrase('distance','<Key-phrase>')
This rule condition evaluates to true, when the input key phrase is not detected before the contributed word and not within the given distance. Distance denotes number of words.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').neContributedWordBeforePhrase('3','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with neContributedWordBeforePhrase('distance','<Key-phrase>'); If the distance is not required then give -1
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').neContributedWordBeforePhrase('-1 ','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with nePhraseBeforeEntityValue('distance','<Key-phrase>')
This rule condition evaluates to true, when the output key phrase is not detected before entity value and not within the given distance. Distance denotes number of words.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').phraseBeforeEntityValue('3','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with nePhraseBeforeEntityValue('distance','<Key-phrase>'); If the distance is not required then give -1
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').nePhraseBeforeEntityValue('-1 ','limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with nePhraseBetweenContributedWordAndEntityValue('<Key-phrase>')
This rule condition evaluates to true, when the output key phrase is detected between the contributed word and the entity value.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit'). nePhraseBetweenContributedWordAndEntityValue('limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Rule with nephraseBetweenEntityValueAndContributedWord('<Key-phrase>')
This rule condition evaluates to true, when the output key phrase is detected between the entity value and contributed word.
{
"skipOnFirstRuleApplied": true,
"skipOnFirstNonTriggeredRule": false,
"priorityThreshold": 10,
"delimeter": ",",
"components": [
{
"name": "Rule0 and Rule1",
"description": "string",
"priority": 1,
"condition": "$.entity('Max Visit Limit').nePhraseBetweenEntityValueAndContributedWord('limit per person','per calendar year','max limit per person','maximum limit per person','max per calendar year','maximum per calendar year','limit','per').isTrue()",
"actions": [
"$.output='Max visit limit is ' + $.value()"
]
}
]
}
Best Practice: Use cases leveraging Java String manipulation functions. Documentation of all the available java string functions can be found in the following location: https://docs.oracle.com/javase/7/docs/api/java/lang/String.html
Configure rules with keyphrases
Given below is a summary of the various conditions that can be used in rule configuration.
Keyphrase Parameter Conditions | Input Value | Condition = True |
containsAllKeyPhrases | One or many key phrases. Multiple keyphrases are separated by comma. | All the provided key phrases are detected in the turn transcript |
containsAnyKeyPhrases | One or many key phrases. Multiple keyphrases are separated by comma. | Any of the provided key phrases are detected in the turn transcript |
containsRegexKeyPhrases | One or many key phrases | All the provided regex patterns are detected in the turn transcript |
containsAnyRegexKeyPhrases | One or many key phrases | Any of the provided regex patterns are detected in the turn transcript |
minOccurs | Minimum number of occurrences of keywords | Number of occurrences of key phrases must be greater than or equal to the minimum occurrence value. |
maxOccurs | Maximum number of occurrences of keyword | Number of occurrences of key phrases must be lesser than or equal to the maximum occurrence value. |
eachMinOccurs | Minimum number of occurrences of each keyword | Number of occurrences of each key phrase must be greater than or equal to each min occurrence value |
eachMaxOccurs | Maximum number of occurrences of each keyword | Number of occurrences of each key phrase must be lesser than or equal to each max occurrence value |
isTrue () | It can be used with any of the above conditions to provide the results | Configured rule conditions output |
contributedWordAfterPhrase('distance','<Key-phrase>') | Given keyphrase and then contributed words | Input key phrase is detected after the contributed word and within the given distance. Distance denotes number of words. |
phraseAfterEntityValue('distance','<Key-phrase>') | Entity value and then given keyphrase | Input key phrase is detected after the entity value and within the given distance. Distance denotes number of words. |
contributedWordBeforePhrase('distance','<Key-phrase>') | Contributed words and then given keyphrase | Input key phrase is detected before the contributed word and within the given distance. Distance denotes number of words. |
phraseBeforeEntityValue('distance','<Key-phrase>') | Given phrase and then entity value | Output key phrase is detected before entity value and within the given distance. Distance denotes number of words. |
phraseBetweenContributedWordAndEntityValue('<Key-phrase>') | Given phrase between contributed word and entity value | Output key phrase is detected between the contributed word and the entity value. |
phraseBetweenEntityValueAndContributedWord('<Key-phrase>') | Given phrase between entity value and contributed word | Output key phrase is detected between the entity value and the contributed word. |
contributedWordAndEntityValueRange('distance') | Distance between contributed word and entity value | Output entity value is detected after contributed word within a specific distance as passed in the condition. Distance denotes number of words |
entityValueAndContributedWordRange('distance') | Distance between entity value and contributed word | Output contributed word is detected after entity value within a specific distance as passed in the condition. Distance denotes number of words. |
neContributedWordAfterPhrase('distance','<Key-phrase>') | The given key phrase should not be placed before contributed word | Input key phrase is not detected after the contributed word and not within the given distance. Distance denotes number of words. |
nePhraseAfterEntityValue('distance','<Key-phrase>') | The given entity value should not be placed before contributed word | Input key phrase is not detected after the entity value and not within the given distance. Distance denotes number of words. |
neContributedWordBeforePhrase(distance,'<Key-phrase>') | The contributed words should not be placed before the keyphrase | Input key phrase is not detected before the contributed word and not within the given distance. Distance denotes number of words. |
nePhraseBeforeEntityValue('distance','<Key-phrase>') | The given key phrase should not be placed before entity value | Output key phrase is not detected before entity value and not within the given distance. Distance denotes number of words. |
nePhraseBetweenContributedWordAndEntityValue('<Key-phrase>') | The given key phrase should not be between contributed word and entity value | Output key phrase is detected between the contributed word and the entity value. |
nePhraseBetweenEntityValueAndContributedWord('<Key-phrase>') | The given key phrase should not be between entity value and contributed word | Output key phrase is detected between the entity value and contributed word. |
Note
If the distance is not required for evaluation then give -1.
Rule output
Analyst can define the value to be shown in contact summary section in 'action' parameter, if more than one value is detected for entity / entities in the conversation. For example, if more than one date is detected for an entity "Date of Service", the date which is to be shown in the contact summary will be configured in the "action" parameter.
The following table shows the various output actions that can be configured in rules.
Actions | Input | Output |
firstValue | N/A | Collect the first value of entity / entities used in the condition. Values are separated by comma. |
lastValue | N/A | Collect the last value of entity / entities used in the condition. Values are separated by comma. |
firstValueOf | one or more entities | Collect the first value of entity / entities extracted, when the applied conditions are satisfied. Values are separated by comma. |
lastValueOf | one or more entities | Collect the last value of entity / entities extracted, when the applied conditions are satisfied. Values are separated by comma. |
value | N/A | Collect all the values of entity / entities used in the condition. Values are separated by comma. |
valueOf | one or more entities | Collect all the values of entity / entities extracted, when the applied conditions are satisfied. Values are separated by comma. |
Rule output ordering configuration
Rule output ordering is a feature that allows the analyst to sort the output (entities) of Rules based on the chronological order of the turns in the conversation, which provides a more intuitive summary and better user experience to the agent.
Actions | Input | Output |
$.value().orderByTimeAsc() | More than one entity | Collect all the values of entities used in the condition. Sort the entities extracted from multiple turns in ascending order. |
$.value().orderByTimeDesc() | More than one entity | Collect all the values of entities used in the condition. Sort the entities extracted from multiple turns in descending order. |
Rule Output Ordering is applicable for all output methods like firstValue, lastValue, value, valueOf, lastValueOf, fistValueOf.
Example for Rule output ordering:
Conversation between customer and an agent
Agent: Hello, I am Michael. How can I help you?
Customer: Hi Michael, my name is Sarah. I am calling to find out about my claim benefit.
Agent: Sure, I can help you.
Action | Keywords with Turn IDs | Output |
$.value().orderByTimeAsc() | Michael (1, 2) Sarah (2) | Michael, Sarah |
$.value().orderByTimeDesc() | Michael (1, 2) Sarah (2) | Sarah, Mic hael |
Refer to the page "Create rules with different conditions" for details of Rule input.
Rule output with split configuration
Rule output with split configuration allows analyst to split the output (entities) of rules in two ways that help an agent to capture a specific portion of the customer conversation.
Split the rule output with respect to start index and end index values.
Split the rule output with respect to regex pattern provided in the output.
Actions | Input | Output |
$.valueOf('entity name').split(int startIndex, int endIndex) | Entity name and start index and end index values at which position the split will occur | Collect the values of entity used in the condition. Split the entity values extracted from the call. |
$.valueOf('entity name').split(string regexpattern) | Entity name and regexpattern | Collect the values of entity used in the condition. Extract the pattern provided in the rule output |
Rule output with split configuration is applicable for all output methods like firstValue, lastValue, value, valueOf, lastValueOf, fistValueOf.
Example for split rule output with respect to start index and end index values:
Conversation between customer and an agent
Agent: Thanks for calling XXX, let me know what is your query?
Customer: I have called to cancel my room booking.
Agent: Sure, I can help you. Can I have your phone number?
Customer: 1234567890
Let us suppose we want to extract the last 4 digits of the pone number. This can be accomplished as follows:
Action | Entity values | Output |
|---|---|---|
$.valueOf('phonenumber').split(7,10) | 1234567890 | 7890 |
Example for split rule output with respect to regex pattern:
Agent: Hello, I am Michael. How can I help you?
Customer: Hi Michael, my name is Sarah. I am calling to find out about my claim benefit.
Agent: Sure, I can help you. Can I have your claim ID?
Customer: ABCD6789XYZ
Let us suppose we want to extract the starting numeric value of claim ID. This can be accomplished as follows:
Action | Entity values | Output |
|---|---|---|
$.valueOf('claimid').split('\\d+') | ABCD6789XYZ | 6789 |
In this example, the regular expression '\\d+' extracts numeric characters from the given input.
Refer to the page "Create rules with different conditions" for details of Rule input.
Rule Output with Uppercase Configuration
The Analyst can configure Rule output (i.e., Entities) to be displayed with uppercase letters, based on a customer's requirements. The Agent will see the extracted Entity values in any of the following ways:
FIRST_OF_EACH_WORD (foew) - Capitalizes the first letter of each word in the extracted Entity value.
FIRST_WORD_OF_VALUE (first) - Capitalizes the first letter of the first word only in the extracted Entity value
all - Capitalizes all letters of the extracted Entity value
Actions | Input | Output |
|---|---|---|
$.valueOf('entityname').capitalizedText('foew') | Entity name and the style in which text should be capitalized. | Collect the Entity value used in the condition, and capitalize the first letter of each word. |
$.valueOf('entityname').capitalizedText('first') | Entity name and the style in which text should be capitalized. | Collect the Entity value used in the condition, and capitalize the first letter of the first word only. |
$.valueOf('entityname').capitalizedText('all') | Entity name and the style in which text should be capitalized. | Collect the Entity value used in the condition, and capitalize all letters. |
Rule output with uppercase configuration is only applicable for output method valueOf.
Examples:
Action | Entity Value | Output |
|---|---|---|
$.valueOf('Disp_resellername').capitalizedText('foew') | american home shield | American Home Shield |
$.valueOf('Disp_resellername').capitalizedText('first') | american home shield | American home shield |
$.valueOf('Disp_resellername').capitalizedText('all') | american home shield | AMERICAN HOME SHIELD |
Configure rules with conversation disposition
Business Analyst can now create rules by passing conversation disposition values as inputs to the rule engine. Earlier, rules could only be configured using entity values.
Note
A conversation disposition is a label that identifies the category or outcome of a call. Conversation dispositions can be configured in U-Assist Aftercall, and each disposition consists of levels of categories (5 levels are allowed in U-Assist Aftercall).
Examples of how this feature will be beneficial are:
If you want a specific summary template to be generated for each disposition type
If you want a particular entity value set according to the call disposition detected
Consider a hospitality client that takes calls to reserve rooms as well as cancel reservations.
An analyst can configure the rules to do the following:
If a call was identified to be of the category "Reservation / Booking" (i.e., Level 1 of the disposition hierarchy is Reservation and Level 2 is Booking), then set the summary template as follows:
Customer Name <>. Guest type <> Member number <> No. of rooms <>. Hotel location <>. Phone number <>. No. of days <>. No. of guests <> Arrival date <> Departure date <> email ID <>. <Phone # shared>. Call transferred <to Dept> for further assistance.
If a call was identified to be of the category "Reservation / Cancel" (i.e., Level 1 of the disposition hierarchy is Reservation and Level 2 is Cancel), then set the summary template as follows:
Customer Name <>. Guest type <> Member number <> Booking ref no. <>. Phone number <>. Reason for cancellation <> email ID <>. <Phone # shared>. Call transferred <to Dept> for further assistance.
How to use this feature:
In the below conversation, the call disposition is identified to be "Benefit Verification". .
Agent: Thanks for calling XXX, let me know what is your query?
Customer: I have called to verify my benefits.
Conditions
The following are the different conditions applied in the rule.
$.disposition().containsLevel1(‘Benefit Verification’).isTrue()
$.disposition().containsHierarchy(‘Benefit Verification’, ‘Dental’).isTrue()
$.disposition().containsLevel1(‘Benefit Verification’).size() == 1
Other operators can be used place of ==, for example - >=, >, <=, <.
The parameters used in this feature are:
containsLevel<num>: Contact categorization in level <num> (e.g. usage: $.disposition().containsLevel1(‘Benefit Verification’).isTrue())
containsHierarchy: Contact categorization hierarchy (e.g. usage: $.disposition().containsHierarchy(‘Benefit Verification’, ‘Dental’).isTrue()
size: The level of the contact categorization to be considered (e.g. usage: $.disposition().containsLevel1(‘Benefit Verification’).size() == 1)
Nested Rules
Rules can be nested within other rules. While creating nested rules, the following criteria are required.
Entities and Rules should be created before a nested rule is included in the rule configuration.
Drafted entities cannot be used in the rule configuration.
Entities once included in the rule configuration cannot be drafted or deleted.
To draft or delete an entity, the entity should be removed from the rule configuration.
Rule configuration must be validated for submitted / drafted entities.
Conditions that can be applied on nested rules are is True() / value().
containsAllKeyPhrases / containsAnyKeyPhrases cannot be applied on the nested rules.
AI Entity
It uses an AI model to extract entities from the transcript.
Rules can also be written using AI entities in addition to rules on NLP and complex entities which were earlier supported. A subset of the functions supported for NLP entities will be supported for AI entities.
While exporting complex entities and rule entities including nested AI entities, the application provides a warning message indicating that AI entities have to be imported first in the target environment for a successful import. For Rule and Complex Entity, U-Assist Aftercall will import the nested AI entities with a validation.
If the AI entities are present in target organization and business process then the application allows the user to import the rule or complex entity.
If the AI entities are not present in target organization and business process then the system throws an exception and prompts the user to create dependent AI entities.
Refer to the page "Rule Configuration for AI entities" for configuration of different conditions and outputs.
Rule Configuration for AI entities
The following are the different conditions and outputs that can be configured for the AI entities. Similar to NLP entities, Rule conditions are applied on the turn transcripts which are obtained as part of the AI entity extraction response.
All function which work based on contributed words will not be applicable and cannot be used for AI entities
AI Entity Extraction Response: [{ "id": "5068", "modelType": "ai", "intentChannel": "Customer", "entityType": "MONEY", "asrValue": "two hundred and fifty six", "preprocessedValue": "256", "normalizedValue": "256", "valid": true, "channel": "Customer", "intentTurnNo": 0, "turnId": [ 3 ], "asrValueCharSpan": {}, "position": 0, "detectedSentence": "Customer: i'll go in for the 256 gigabyte iphone 12 ." }]
normalizedValue - Normalized value, which will be used in the rule output.
turnId - Turn id of the transcription.
detectedSentence - Turn transcript.
intentChannel - Keyphrase identified channel.
channel - Entity extracted channel.
isValid - True/False - True indicates if the date value extracted by the NLP is valid - mm/dd/yyyy.
preprocessedValue - Value as extracted present in the turn transcript. It is used in the rule condition execution.
AI Entity Rule Configuration:
Contains | Negations | Condition | Output |
containsAnyKeyPhrases | nePhraseBeforeEntityValue | isTrue | isTrue |
containsAnyRegexKeyPhrases | phraseBeforeEntityValue | value | value |
containsAllKeyPhrases | nePhraseAfterEntityValue | data | firstValue |
containsAllRegexKeyPhrases | phraseAfterEntityValue | lastValue | |
firstValueOf | |||
lastValueOf | |||
valueOf |
Negations | Distance | KeyPhrases | Description |
nePhraseBeforeEntityValue | Y | Y | All the keyphrases provided should not be present before entity value in the turn transcript. Distance indicates the number of words till the search should be executed. |
phraseBeforeEntityValue | Y | Y | Any of the keyphrases provided should be present before entity value in the turn transcript. Distance indicates the number of words till the search should be executed. |
nePhraseAfterEntityValue | Y | Y | All the keyphrases provided should not be present after entity value in the turn transcript. Distance indicates the number of words till the search should be executed. |
phraseAfterEntityValue | Y | Y | Any of the keyphrases provided should be present after entity value in the turn transcript. Distance indicates the number of words till the search should be executed. |
Note
To differentiate between AI and NLP entity in a condition of Rule Configuration, a new API named 'aiEntity' is introduced. All AI entities must use this API method to configure the Rule.
For example, Phone_Number is an AI entity so the configuration should start with aiEntity.
Entity Catalog
It is a catalog of entities specific to a particular deployment. The entities in the entity catalog are used to create an AI model for the particular client.
The entity catalog allows the Business Analyst to import entities that have been pre-trained by AI models, which simplifies and reduces the time to configure entity and intent recognition which will improve overall system operation. The catalog reference list will be at the Tenant level. Multiple entity catalog lists at organization/business process level are not allowed. Analysts cannot edit/add entities in the entity catalog reference.
Any change to catalog reference should be considered as an implementation change request as it will have significant impacts to annotation for model training and accuracy calculations.
 |
In the Search field, enter a minimum of 3 characters to search by entity name and entity type from the list.
View Entity Details
Analyst can view the list of entities along with description, entity source (NLP, Rule or AI), entity catalog reference, entity type and status for the business process. All the entities which are imported using the Import from Model option will have the source as “AI” in the "Source" column. All the other methods of entities which were created prior to 2.4 will have a source as “NLP”. For entities which are created with 'Rule' type, the source will be displayed as "Rule". For all the AI entities, you can view only the status "Trained". For NLP and Rule entities, you can view the following values in the status column.
Draft - Entities which are saved as draft while being defined or configured
Submitted - Entities which are successfully submitted
Trained - Entities which are trained.
The number of entities drafted, submitted and trained for business process will be displayed on the right side of page.
 |
Filter Entities
Analyst can filter the list of entities based on Status and Entity Type.
Status - Draft, Submitted, Trained
Entity Type - List of all Entity Types
 |
The filtered set of Entities will be listed. If Draft is included in filter option, then Draft will be displayed on top followed by Submitted and Trained.
Filter preferences can be retained for the user during the session when the user is logged in.
Search Entity
Analyst can search for an Entity from the list of Entities within a Business Process.
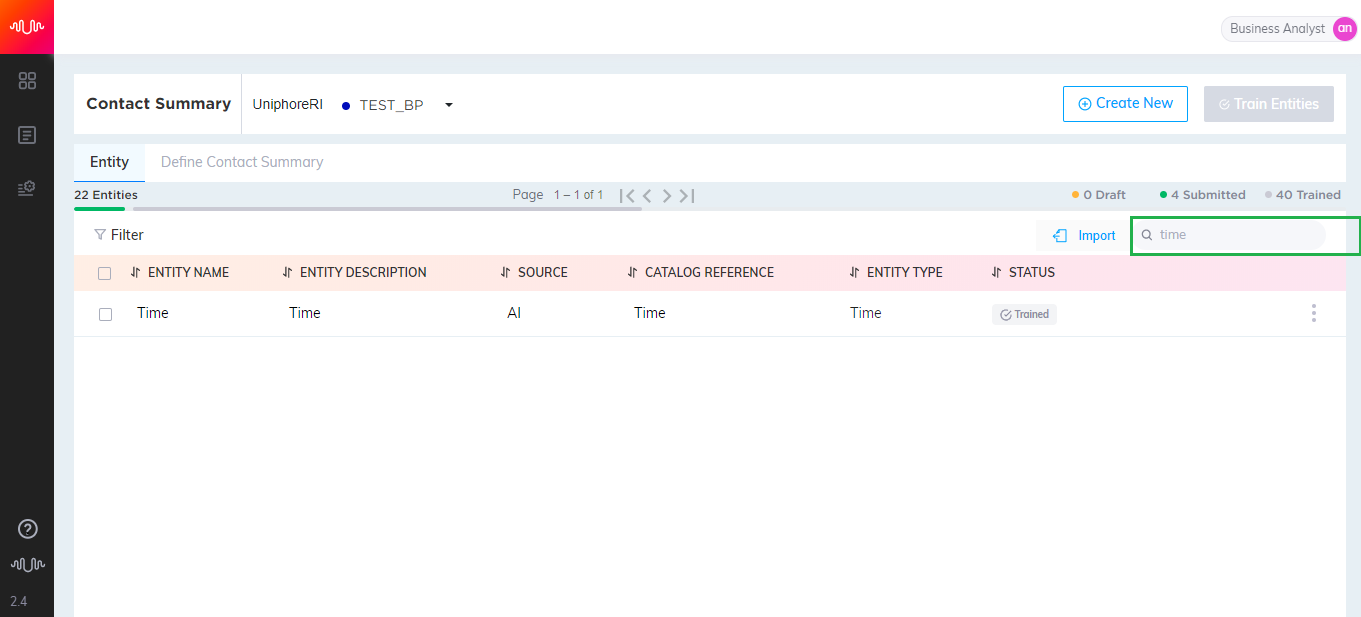 |
In the Search field, enter a minimum of 3 characters to search by Entity Name and Description from the list.
Sort Entities
Analyst can sort the Entities alphabetically in both ascending and descending order by Entity Name, Description, Entity Type and Status.
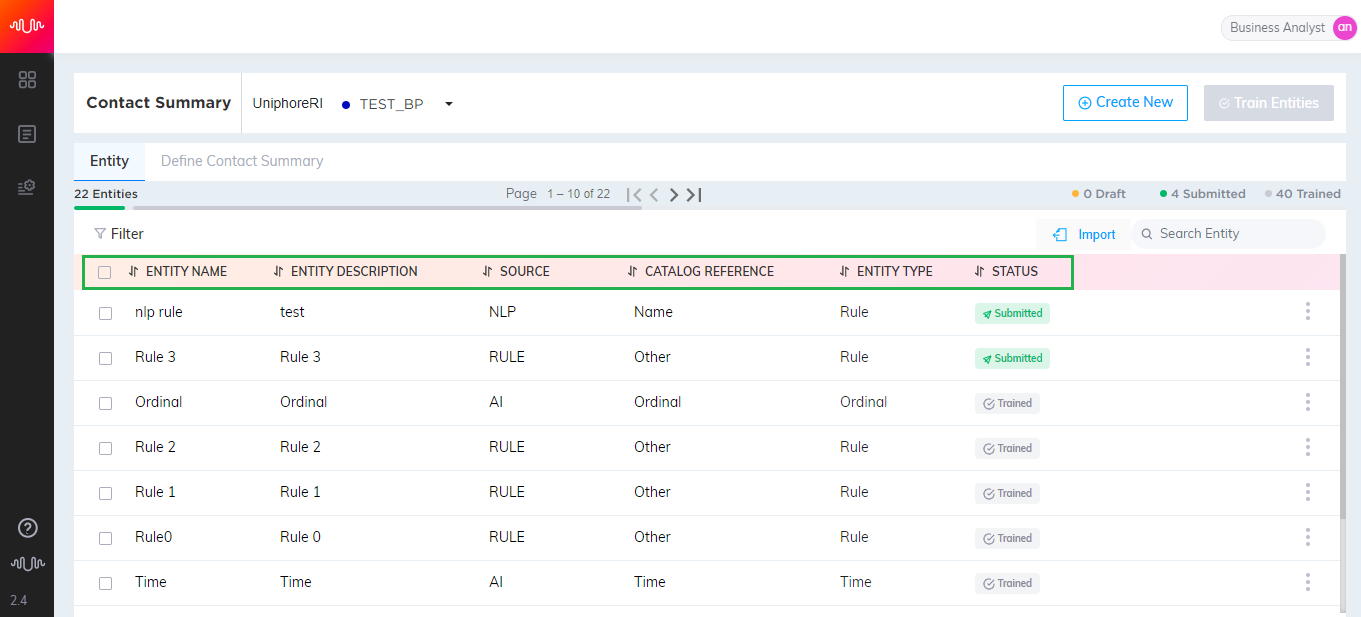 |
By default, Analyst can see the list of Entities with Draft status with the most recently created on top of the list.
Copy Entities from Business Process
Analyst can copy a set of entities from a Business Process to multiple Business Processes.
Select the list of entities from the source business process by choosing the check boxes and click Copy to Business Process button.
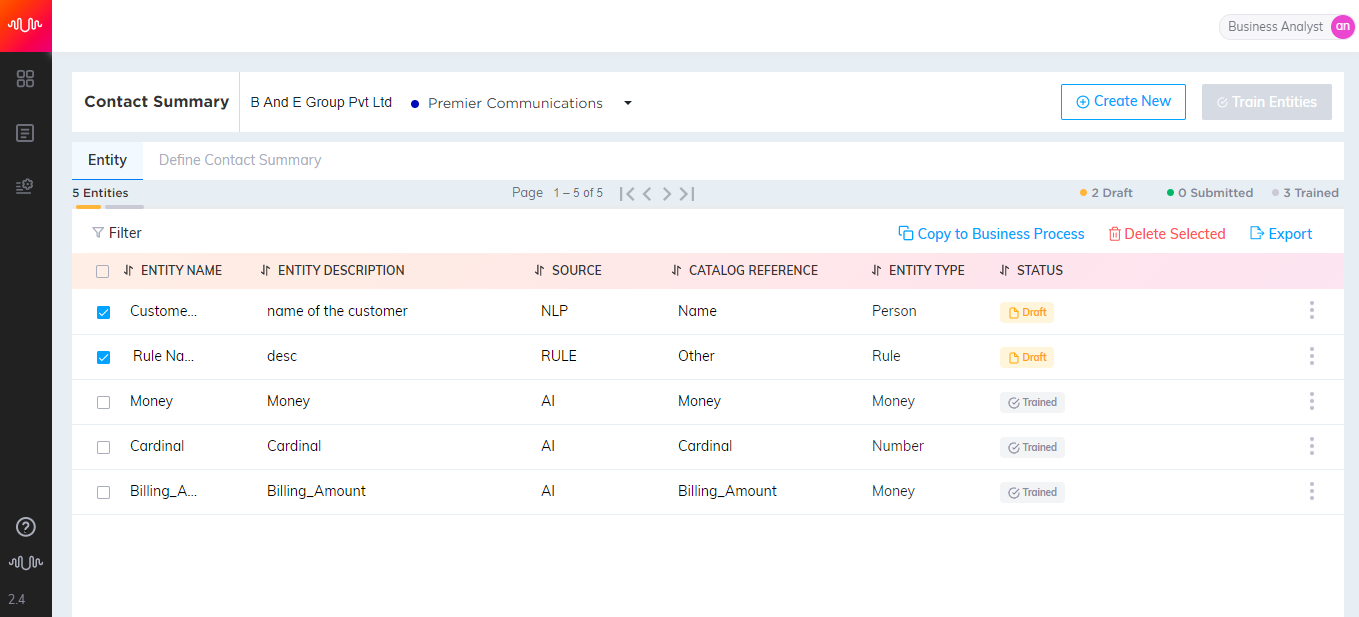
The number of entities selected will be displayed as shown below.
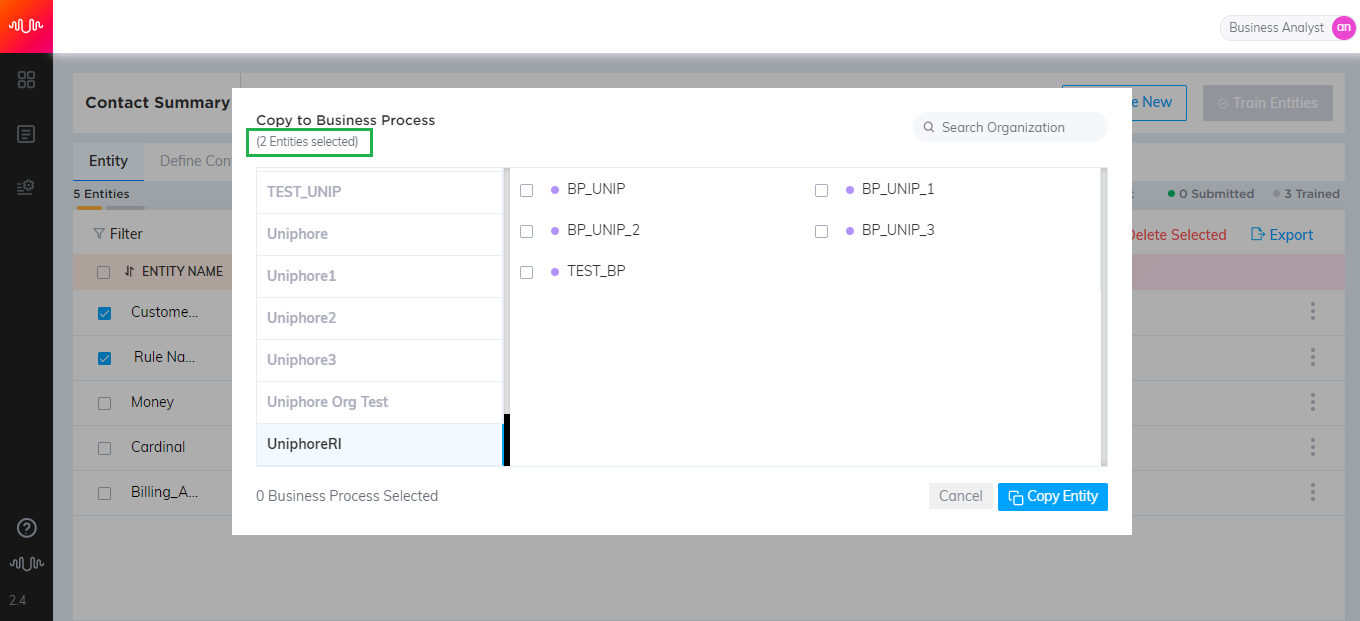
Select the organization from the left pane. The corresponding business processes will be displayed based on the organization selected.
In the Search field, enter a minimum of 3 characters to search for a specific business process.
Select the business processes from which the set of entities is to be copied. The number of business processes selected will be displayed at the bottom of the window.
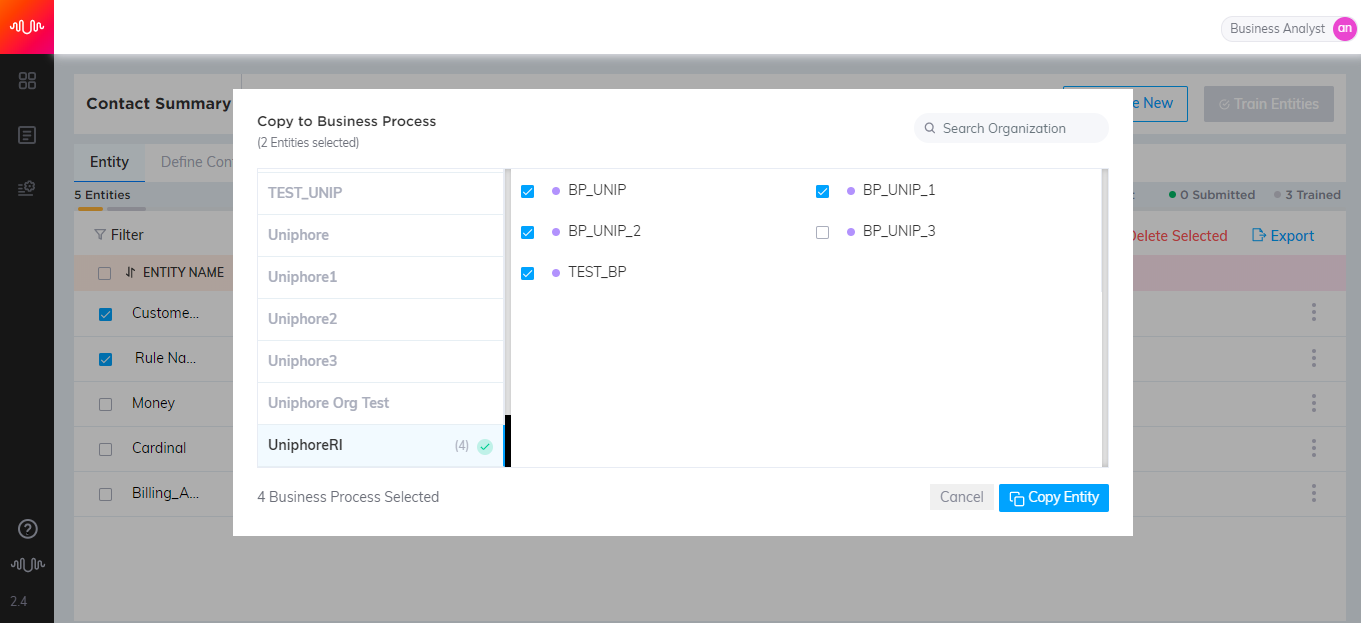
Click Copy Entity button to copy the selected entities into business processes.
Click Cancel button to cancel the selection of entities.
Train, Edit and Delete Entities
Analyst can edit, train and delete all the NLP and Rule entities from the Entity list page. For AI entities, you have an only option to delete the entities.
Click Edit button to edit the entity which is in draft status.
Click View Details button to view the configured entity details such as Entity Type, Match Type, Entity Extraction Channel, Keyphrase Matching Channel, Entity Position, etc.
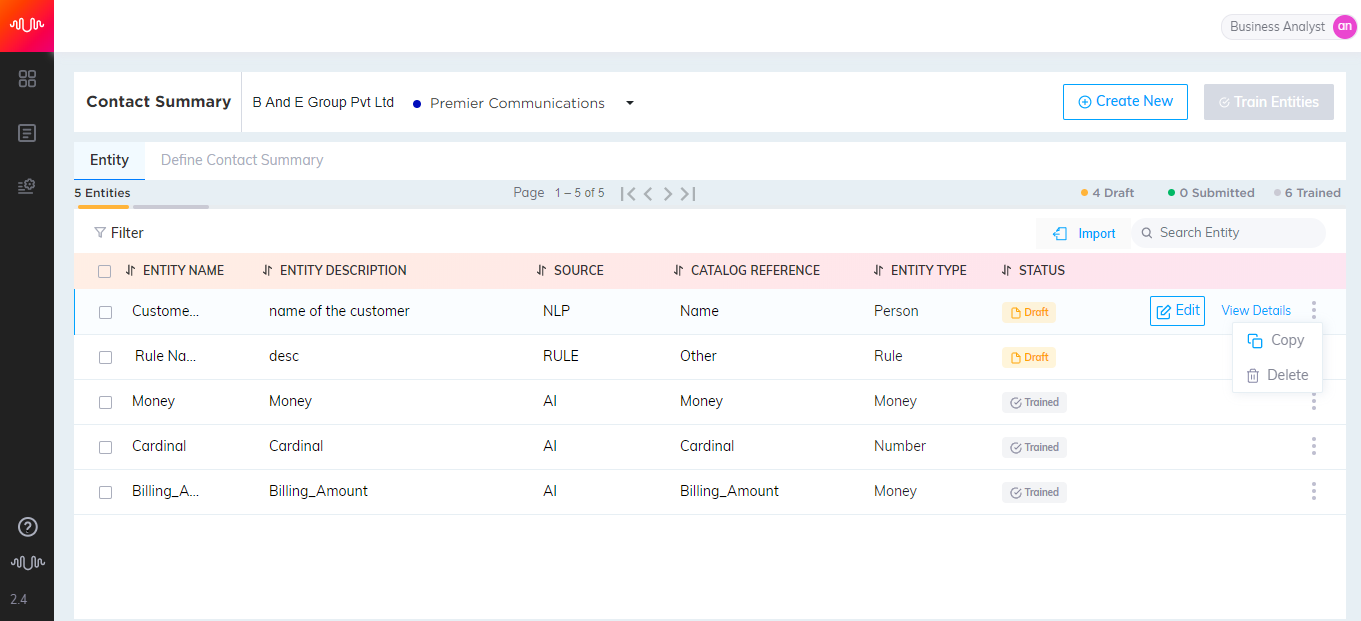
Click on this ellipsis icon
 in respective to the NLP and Rule entities to edit, delete or copy entities in Submitted, Trained, Draft status.
in respective to the NLP and Rule entities to edit, delete or copy entities in Submitted, Trained, Draft status.Select the check boxes corresponding to the NLP and Rule Entities which are in Submitted status and click Train button on top of the page to train the Entities. After training, the status will be changed from 'Submitted' to 'Trained' and a confirmation message will be displayed as "Entity Trained Successfully." When the Entities are being Trained through the NLP layer, Analyst cannot perform any actions within the Business Process.
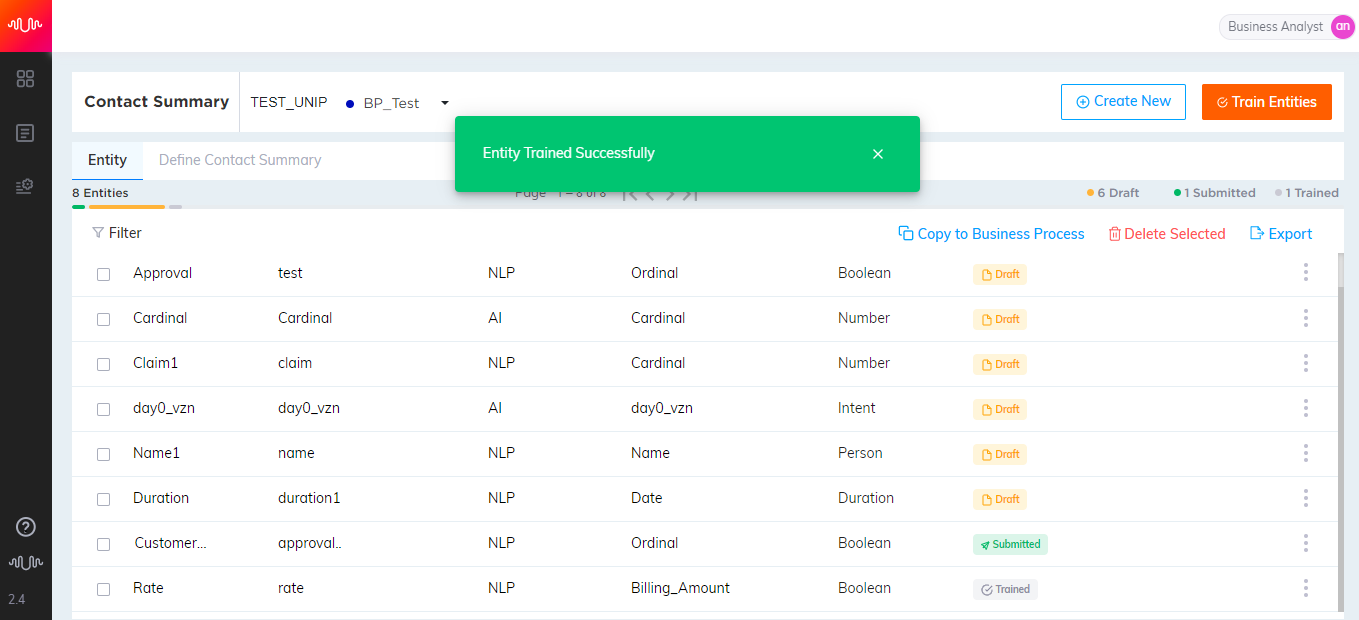
If the language mapping is not available for the selected business process, a warning message will be displayed while training the entities. Information on how to map languages to business processes can be found in the "U-Assist Aftercall Admin Guide".
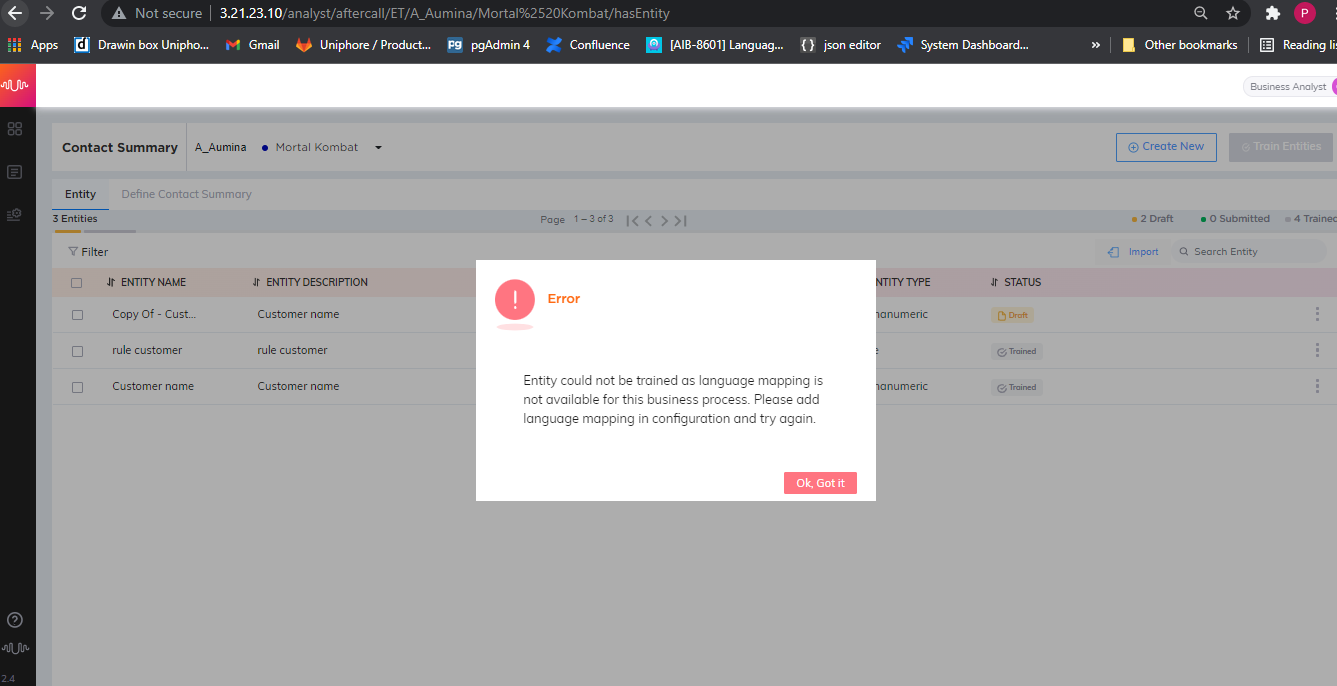
Export and Import of Entities
Export Entities
Analyst can export only NLP and Rule entities. For AI entities, Export option is disabled.
Select the entity to be exported.
Click Export button.
The selected entity will be downloaded in JSON format. This JSON file includes CTI language code, ISO language code, entity name, description, entity type, catalog reference, status and other configuration details.
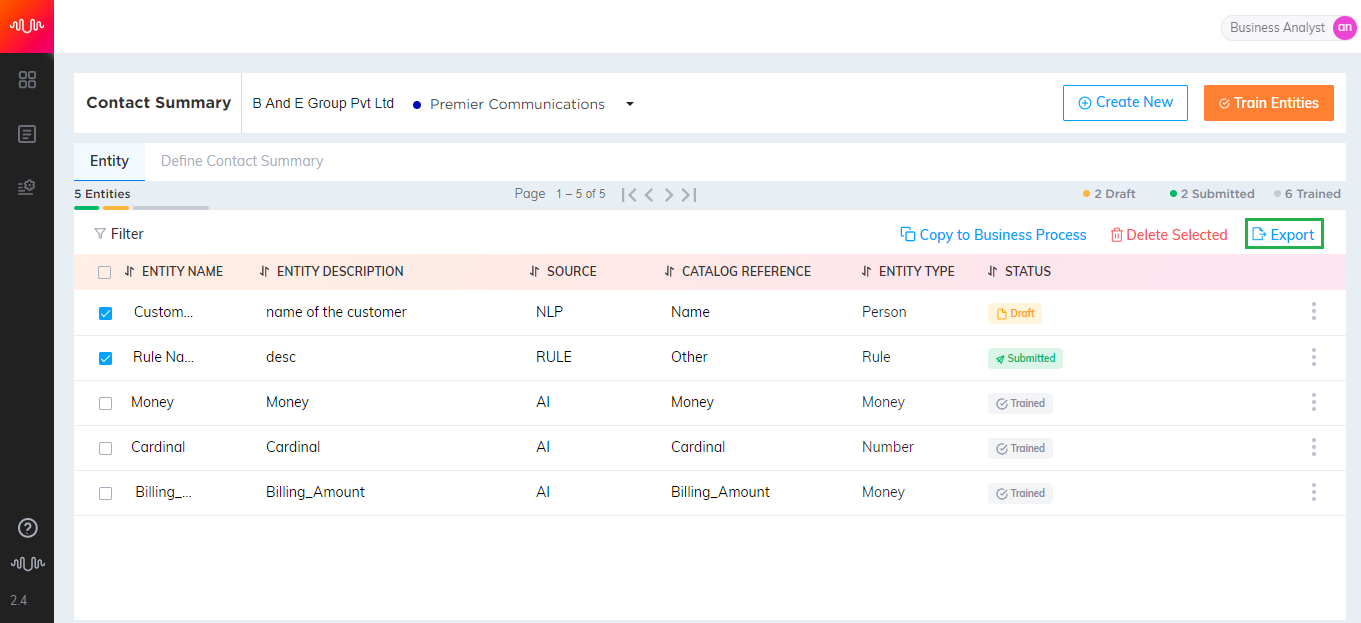
Sample JSON file:
{ "ctiLanguageCode": "EUU", "isoLanguageCode": "en-us", "exportEntityBeans": [ { "defineEntity": { "id": 0, "referenceName": "My Name", "name": "My Name", "description": "My Name", "entityType": "PERSON", "noOfChar": 0, "defaultValue": "", "boolTrueValue": null, "entityTextIfFalse": null, "catalogReference": "Name", "sourceType": "NLP", "trained": true, "saved": true }, "configureEntity": { "name": "My Name", "inputParams": [ { "keyPhrases": [ { "keywordName": "my name is", "isNew": null, "categoryId": 0 } ], "keyphraseMatchingChannel": "Agent", "entityExtractionChannel": "Agent", "entityPosition": "Suffix", "turnPosition": "Same", "fuzzyMatch": true } ], "outputParams": { "keyPhrase": null, "entityPosition": null } }, "ruleConfig": null, "apiConfig": null, "nestedEntities": null, "nestedAiEntities": null } ]}While exporting complex entities and rule entities including nested AI entities, the application provides a warning message indicating that AI entities have to be imported first in the target environment for a successful import.
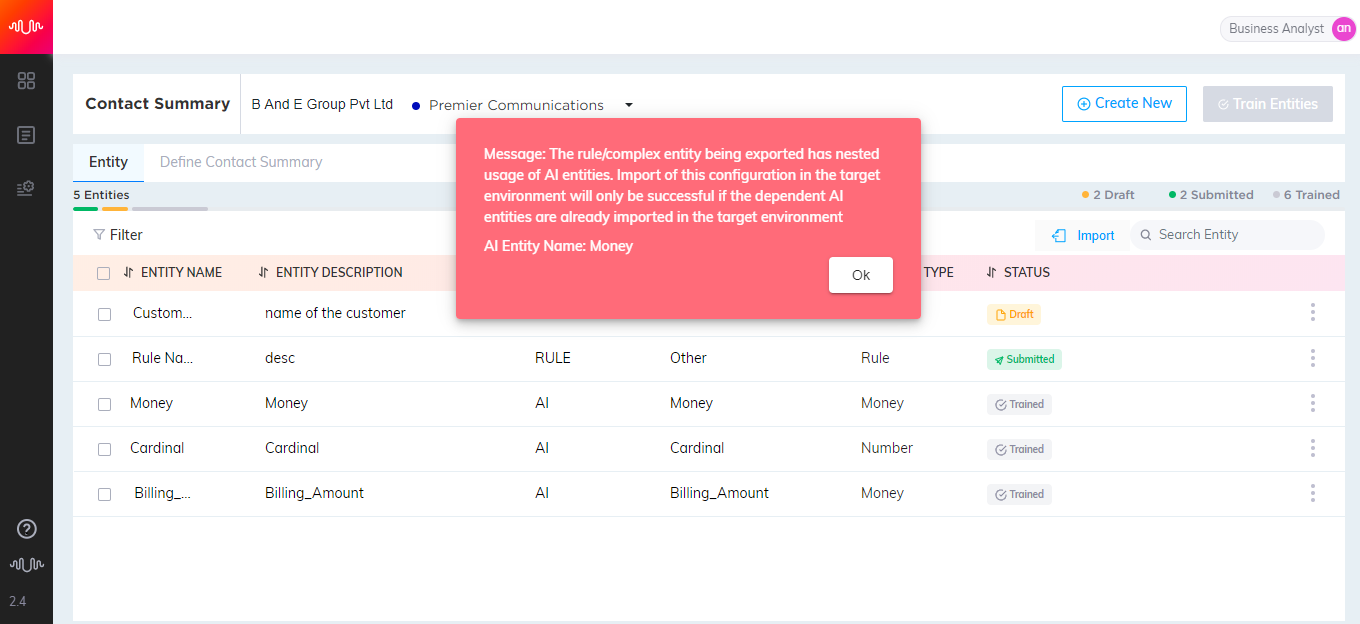 |
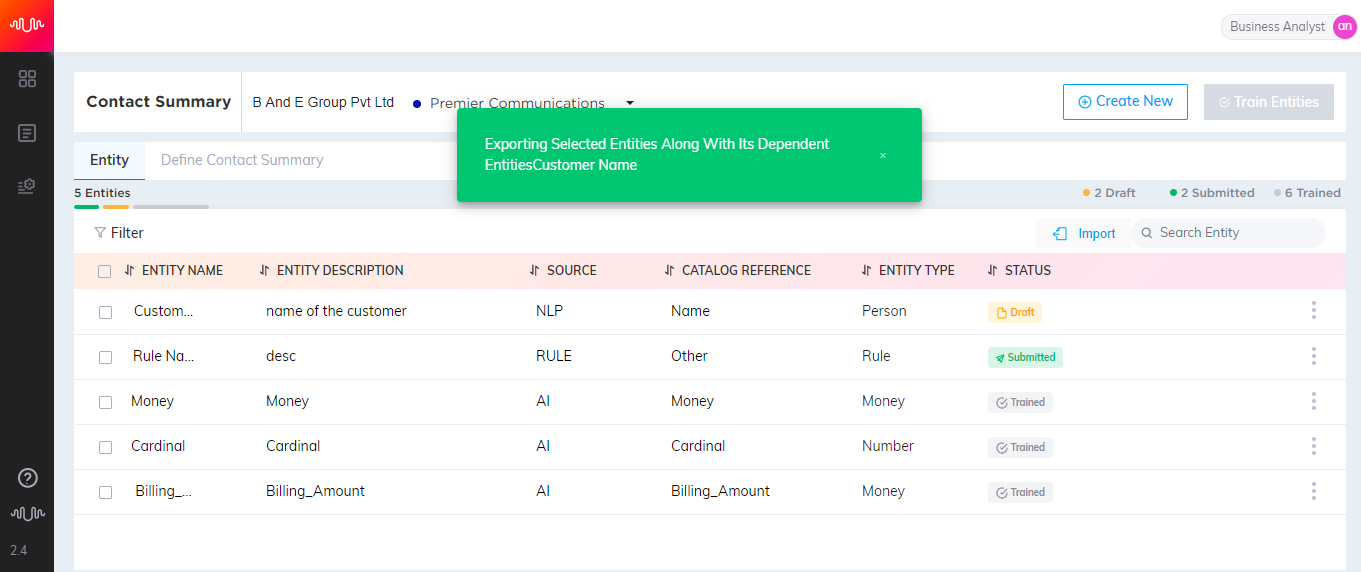 |
Import Entities
Analyst can import entities from a file, and can also import entities that have been pre-trained by AI models. The latter is done by using the Import from Model functionality in the Entity listing page. In the Entity Listing page, all the entities which are imported using the Import from Model option will have the source as “AI” in the 'Source' column
Click Import button. You have an option to import AI entities and NLP entities.
 |
Import from file
Select Import from file option. The window to select file will open.
Select the entity file (JSON file) and click OK. The imported entities will be listed in the Entity List page.
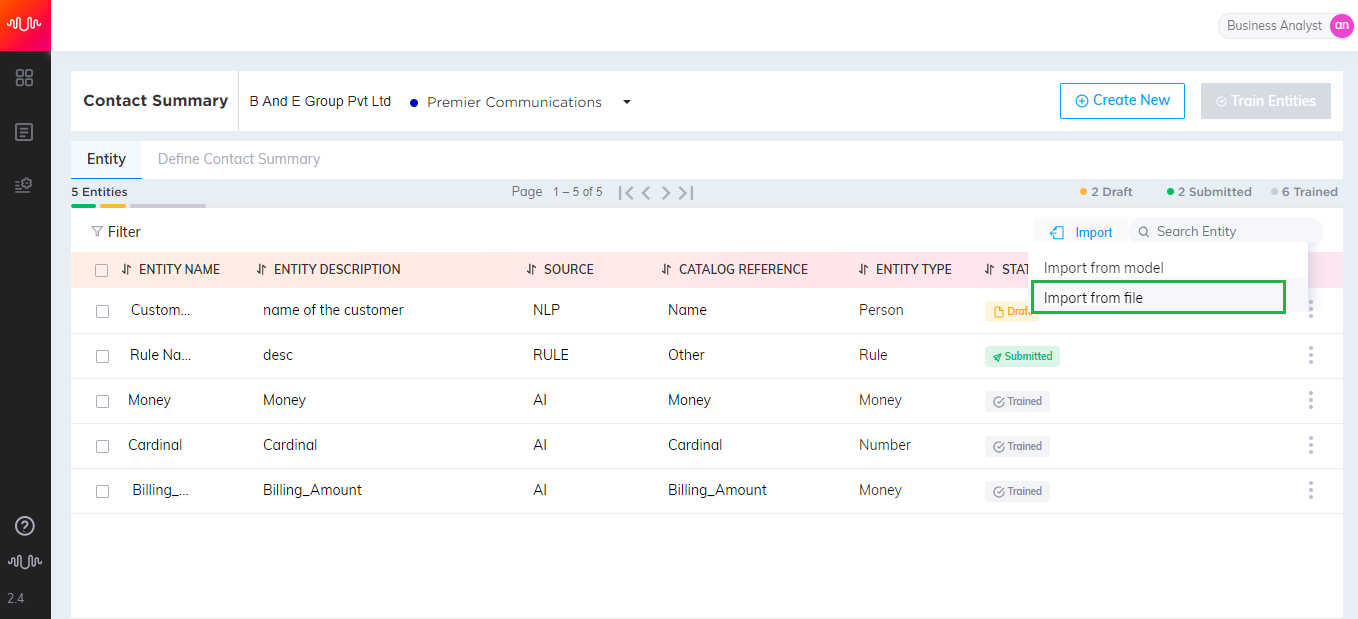
Note
Exported files from previous versions need to be in the current JSON structure for successful import into U-Assist 23.2. Refer to the "Sample JSON file" in the Export Entities section.
Entities which are created prior to 2.4 cannot be imported to version 2.4.x and above.
For Rule and Complex Entities, U-Assist Aftercall will import the nested AI entities with a validation.
If the AI entities are present in target organization and business process then the application allows the user to import.
If the AI entities are not present in target organization and business process then the system prompts the user to create dependent AI entities.
Import Conditions:
Language of the import file should be same as language of the target environment.
Only valid JSON file should be imported.
If any of the above conditions are not satisfied, a warning message will be displayed.
Warning
Please do not edit an exported JSON file unless you have to modify the contents for a cross-version import. Errors in the JSON structure or contents will cause imports to fail.
Import from model
Select Import from model option. You can view the list of AI entities model. Each model includes version number, number of entities and date when the model is tested.
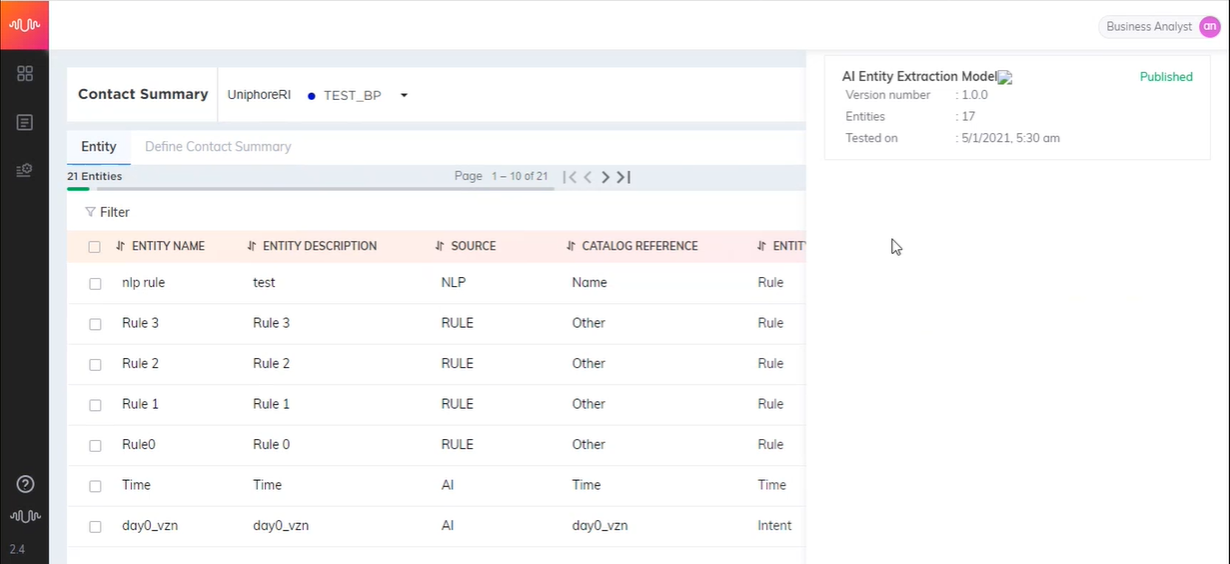
Click on the model to view all the AI entities available in this model. You can also view the entity catalog reference and the status of each entity whether it is already exist in the business process or not.
If the entity is already exist in the respective business process, the status is shown as "Imported". If the entity does not exist in the business process, the status is shown as "Not Imported". You can only import entities which are not present in the destination business process. Intent is also imported as an Entity.
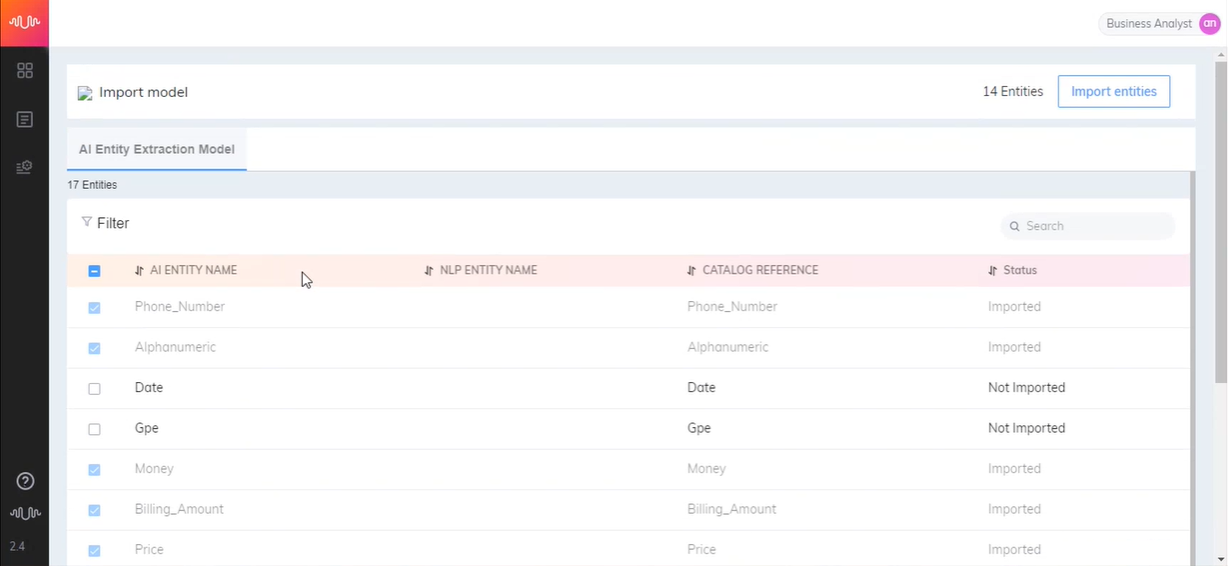
Select the entities to be imported into the business process and click Import entities button.
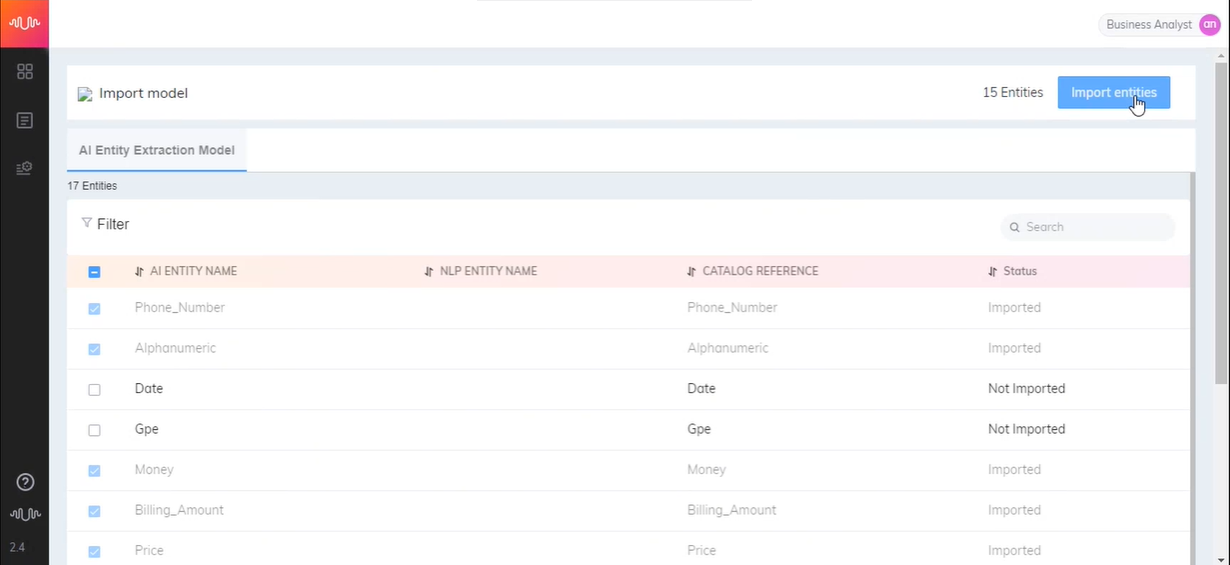
After successfully importing entities, you can view the imported entities in the Entity list page.