Automatic Speech Recognition (ASR)
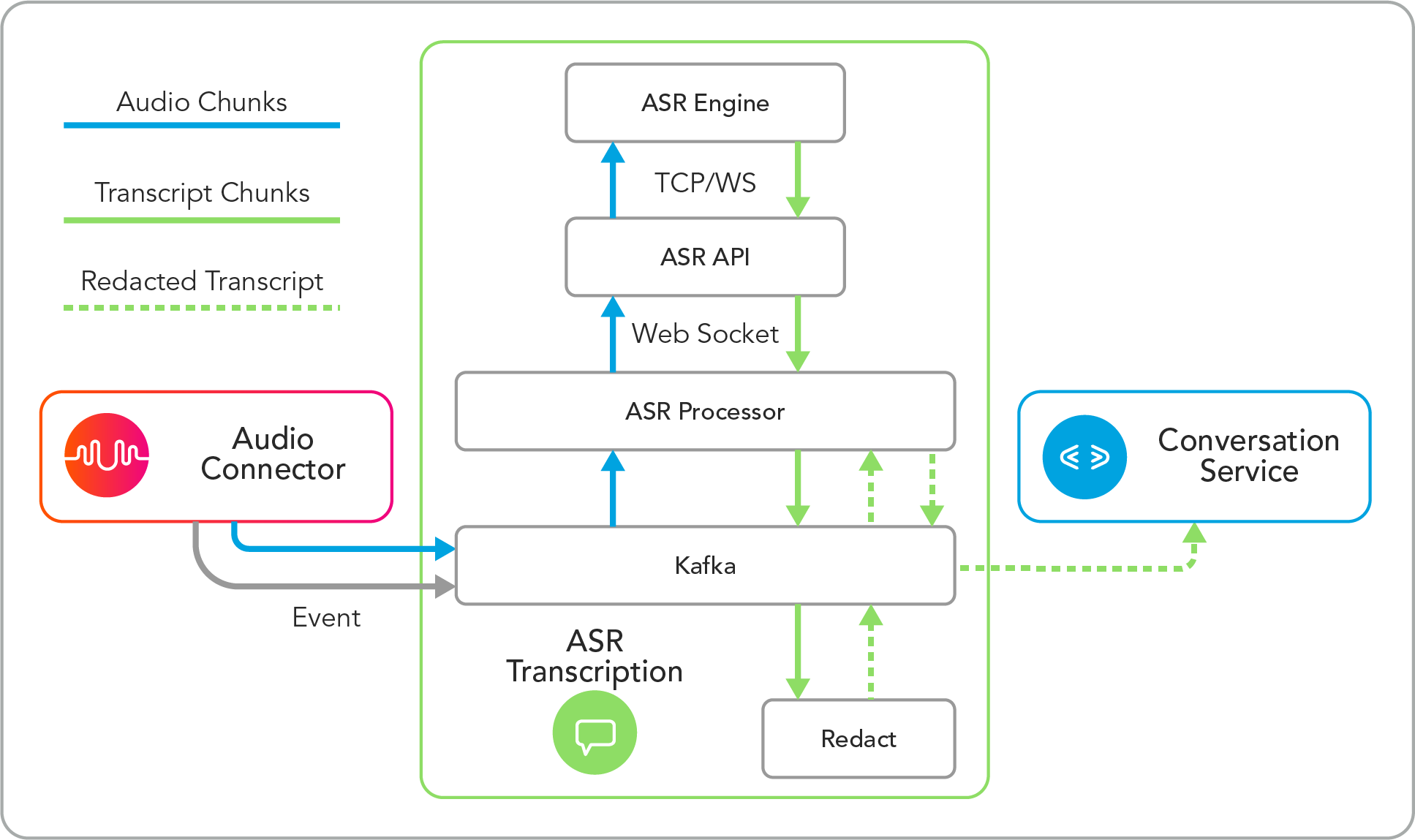
Automatic Speech Recognition (ASR) transcribes spoken language into text. The following steps summarize the journey that the U-Capture recorded call audio goes on to become an accurate transcript with sensitive data redacted:
As the audio connector receives realtime call audio and streams the audio and call event to Kafka (in the ASR) in the form of 3 second audio chunks.
The audio chunk is then passed to the ASR Processor where the language of the audio is determined.
Over Web Socket the audio chunk and language is passed to the ASR API where it can be sent to the appropriate ASR Engine for transcription, which engine and which connection method depends on the language.
The ASR Engine receives the audio chunk and converts it into text (a transcript chunk), then sends the transcript chunk to the ASR API where it's then sent to the ASR Processor.
The ASR Processor sends the transcript chunk to Kafka, where it's routed to the designated language-specific Redact service.
The Redact service will remove any sensitive data and replace it with either asterisks or labels denoting the redacted content's category.
The redacted transcript is then sent to the ASR Processor via Kafka where it is then sent via Kafka to the Conversation Service and paired with the call's other metadata.
Note
The various connections to Kafka use TCP, for an introduction to Kafka, see the official Apache Kafka intro here.
Note
The above summarizes how call audio is processed by the ASR for U-Capture, the ASR has additional features that are used by other applications, see the relevant documentation for details.